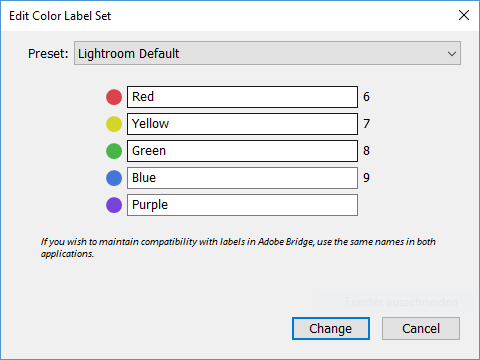
Haben Sie schon mal Farbmarkierungen in Lightroom verwendet, um Ihre Fotos zu organisieren? Vielleicht überrascht es Sie, dass diese Farbmarkierungen ihnen Namen nicht ganz zu Recht tragen. Den Fotos werden keine Farben zugewiesen, sondern eine Zeichenkette, die den Namen der Farbe beinhaltet. Das können Sie leicht selbst ausprobieren. Starten Sie Lightroom, suchen sich ein Bild aus und setzen Sie die Farbmarkierung auf rot, z. B. mit der Taste „6“. Abhängig von Ihrer Konfiguration zeigt Lightroom Ihnen jetzt einen roten Rahmen um das Bild, fügt in der Gitteransicht einen rötlichen Hintergrund hinzu oder zeigt ein kleines rotes Kästchen unter dem Bild. Nun lassen Sie sich die Standard-Metadaten anzeigen. Sie finden ein Feld namens „Beschriftung“. Und dort? Dort steht „Rot“ als Text, nicht die Farbe Rot selbst.
Das Feld trägt seinen deutschen Namen zu Recht, Sie können einfach einen anderen Text eintragen. Tippen Sie doch mal „Grün“ und schauen dann auf die angezeigte Farbe. Was Sie eintragen, steht Ihnen frei. Nehmen wir an, Sie wollen ein Foto als fertig markieren, dann schreiben Sie einfach „fertig“. Jetzt wird keine Farbe angezeigt. Hatten Sie das erwartet?
Farbmarkierungssätze
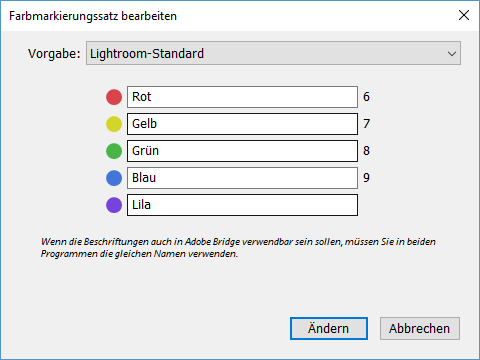
Wenn im Feld „Beschriftung“ nur Text steht, wie weiß Lightroom dann, welche Farbe es anzeigen soll? Wie funktioniert das mit verschiedenen Sprachen? Das was ich „Gelb“ nenne, bezeichnet ein Engländer als „Yellow“, obwohl wir beide die gleiche Farbe meinen. Der Schlüssel sind die Farbmarkierungssätze. Sie finden diese im Menü unter „Metadaten – Farbmarkierungssätze“. Lightroom wird mit drei Standardsätzen ausgeliefert: „Lightroom-Standard“, „Bridge-Standard“ und „Status prüfen“. Außerdem finden Sie im Menü die Möglichkeit, die Farbmarkierungssätze zu „Bearbeiten…“. Probieren Sie es einfach mal aus, Sie sehen:
Das ist auch schon das ganze Geheimnis. Lightroom liest das Feld „Beschriftung“ aus und prüft, ob es im aktuellen Farbmarkierungssatz eine Farbzuordnung für den Text gibt. Der Text ist dabei nahezu beliebig. Bei „Lightroom-Standard“ wurden einfach die Farbbezeichnungen verwendet, die anderen beiden nutzen andere Texte und sind gute Beispiele für möglichen Einsatz. Sie können Ihre eigenen Farbmarkierungssätze speichern.
Übrigens verändert das Umschalten zwischen Farbmarkierungssätzen den Inhalt des „Beschriftung“-Felds nicht, sie können also verschiedene Sätze für unterschiedliche Zwecke anlegen und nutzen. Eine Sache sollten sie jedoch beachten: es kann nur eine Beschriftung pro Foto geben. Wenn Sie also mit „Lightroom-Standard“ ein Bild mit „Rot“ markieren, dann zu „Bridge-Standard“ wechseln, um dasselbe Bild als zweite Wahl zu markieren, dann wird von der Beschreibung“Rot“ nichts bleiben.
Ich überlasse es Ihnen, herauszufinden, wie das mit verschiedenen Sprachen funktioniert.
Seit einiger Zeit versuche ich mich an Makros kleiner Insekten. Im Moment verwende ich ein Sigma MACRO 105mm F2.8 DG mit Kenko Zwischenringen, meist mit einem 20 mm Ring, an meiner Canon EOS R. Noch bin ich ziemlich am Anfang, aber es kristallisieren sich ein paar Erkenntnisse heraus.
Es gibt zu wenig Licht!
Die theoretische Überlegung, dass die Schärfentiefe selbst für eine Fliege nicht ausreichen wird, wenn ich die Blende aufdrehe, um möglichst viel Licht nutzen zu können, finde ich praktisch sofort bestätigt. Die Blende muss soweit zu, wie es nur geht. Und da kommen wir schon zur zweiten Theorie, die bestätigt wird: auch wenn das Objektiv Blende 22 zulässt: das bringt nichts. Ab Blende 16 wird das Bild durch Beugung an der Blendenöffnung sichtbar unschärfer, Blende 14 ist anscheinend das Optimum.
Meine neu R kann weiter gehen als meine alte 7D , aber auch sie hat natürlich ihre Grenzen. Gerade wenn es um sehr feine Details geht, stört ein Bildrauschen, das man auch bei ISO 800 sieht. In anderen Kontexten, z. B. bei der Theaterphotographie, toleriere ich das Rauschen bis ISO 3200, ggf. sogar mehr. Bei den Insekten ungern. Meist will ich das Bild noch ein wenig beschneiden, die Qualität sollte optimal sein. Also runter auf ISO 100.
Um bei ISO 100 und Blende 14 arbeiten zu können braucht man entweder sehr viel Licht oder lange Belichtungszeiten. Ich habe daher versucht, die Kamera auf ein Stativ zu setzen und mit Belichtungszeiten um 1/4 herum zum Ziel zu kommen. Das hat sich für mich nicht bewährt. Erstens sind meine Motive meist längst entnervt entschwunden, bis mein Stativ in der richtigen Position steht, zweitens bewegen die Biester sich. Selbst Fliegen, die scheinbar still sitzen, bewegen oft den Hinterkörper. Ich bin kein Biologe, aber ich vermute, es handelt sich um Atembewegungen. Daher versuche ich, Belichtungszeiten um 1/200 bis 1/250 Sekunde zu erreichen. Das große Stativ lasse ich weg, versuche nur, ohnehin vorhandene Objekte als Stütze zu verwenden, oder nutze ein Einbein.
Trotz Mittagssonne zu langsam
Leider ist dann immer noch, selbst in der prallen Mittagssonne (zu deren Qualitäten später mehr), meist zu wenig Licht da.
Mehr Licht muss her – Blitzen!
Nach kurzer Suche im Internet ist mir klar: einen Makroblitz mit zwei separat ansteuerbaren Hälften, ob nun Ring oder kleine einzelne Blitze, würde ich gern mal ausprobieren, für den Anfang ist er mir aber zu teuer (bzw. ich traue den Billigangeboten nicht über den Weg). Also heißt es ausprobieren und basteln.
Die erste Idee, einfach den Austeckblitz nach unten zu justieren, findet schnell ihre Grenzen. Die Dinger sind nicht dafür gemacht, Objekte in kurzem Abstand vor der Linse zu beleuchten. Besser ging es schon mit einer am Blitz befestigten Reflektorfläche, die das Licht nach unten streut. Die Technik hat aber auch zwei Nachteile: Es hängt so viel Gewicht am Blitzkopf, dass der immer nach unten knickt. Meine Blitze jedenfalls lassen sich in verschiedene Winkel über Einrastpositionen einstellen – das Einrasten ist aber viel zu zart für den Reflektor. Und zweitens kommt das Licht jetzt immer von oben – sieht auch doof aus.
Als nächstes habe ich versucht, den Blitz über Funkauslöser anzusteuern und ihn mit dem Reflektor seitlich neben die Kamera zu halten. Mein Fazit dazu: ich habe mindestens eine Hand zu wenig. Geht also auch nicht.
Also wieder im Internet suchen und über Bastellösungen nachdenken. Eine Idee, die ich vielleicht auch noch mal weiterverfolge, ist eine Blitzschiene unter der Kamera, auf die man dann zwei vertikale kurze Schienen montiert, die ihrereseits zwei Aufsteckblitze halten, die nach vorn zeigen, so dass ihre Blitzröhren rechts und links des Objektives zum liegen kommen. Im Moment schätze ich das als zu sperrig und wackelig ein. Es gibt ein paar ähnliche Ansätze im Zubehörhandel, die Nutzerkommentare bestätigen meine Bedenken eher.
Daher habe ich mich entschlossen, erst mal bei einem Blitz zu bleiben. Warum sollte ich auch zwei brauchen? Die Antwort ist schnell gefunden: vielleicht wegen der Schatten.
Portraits, Licht und Schatten
Harte Schatten bei direkter Sonneneinstrahlung
Ein Aufsteckblitz ist zwar nicht wirklich eine punktförmige Lichtquelle, aber die Fläche, von der das Licht ausgeht, ist im Vergleich mit den photographierten Objekten so klein, dass hinter diesen harte Schlagschatten auftreten. Die werden meist als unschön empfunden. Hat man zwei Lichtquellen, kann die eine die Schatten, die die andere produziert, ausleuchten. Kann man die beiden Quellen dann noch getrennt in der Helligkeit regeln, lässt sich die Ausleuchtung schon recht gut beeinflussen.
Das wird auch oft bei Portraitaufnahmen in Studios gemacht, da gibt es einen typischen Aufbau mit einem Modell-Licht (Key) und einem Aufhelllicht (Fill), letzteres ist oft auch nur ein Reflektor. Um im zweidimensionalen Photo einen plastischen Eindruck zu erreichen, brauchen wir die Schatten übrigens schon, ganz weg wollen wir sie nicht haben, sonst wirkt das Bild sehr flach, nur weich und mit ein wenig Richtung. Bei Portraits gilt es als klassisch schön, wenn das Licht in etwa so fällt, wie wir es von natürlicher Beleuchtung kennen, also schräg von oben und meist ein wenig von der Seite (ich will hier nicht in die Details gehen, es gibt verschiedenste Ausleuchtungsvarianten und Ausnahmen von fast allem).
Weiche Schatten bei leicht bedecktem Himmel
Will man die Schatten weich kriegen, ist entscheidend, dass das Licht nicht nur aus einer, oder einigen wenigen festen Richtungen kommt. Ist die Lichtquelle ein Punkt, so kommt das Licht immer nur aus genau einer Richtung, ist die Lichtquelle eine Fläche, so fällt Licht über einen bestimmten Raumwinkel ein und es ergibt sich ein weicher Übergang zwischen Licht und Schatten.
Das kann man leicht draußen beobachten. Die Sonne ist zwar groß, aber weit weg, daher erscheint sie in einem kleinen Raumwinkel, nahezu punktförmig. Jeder kennt die harten, klaren Schatten, die Sonnenlicht wirft. An bedeckten Tagen wird das einfallende Sonnenlicht jedoch durch die Wolken gestreut, der gesamte Himmel wirkt leuchtend und trägt zur Licht und Schatten bei. Weil das Licht „aus allen Richtungen“ kommt, sieht man fast keine und nur sehr weiche Schatten. Tage mit nicht zu dichter Bewölkung, aber eben auch nicht klarem Himmel sind ideal für Portraits im Freien.
Der Raumwinkel hängt ab von der Größe der Lichtquelle und dem Abstand zum beleuchteten Objekt. Bei Portraits und Studioblitzen würde ich das Verhältnis zwischen Größe der Lichtquelle (erst mal der nackten Blitzröhre) und dem Objekt auf in der Größenordnung 1:10 schätzen, den Abstand auf typischerweise 1:3. Also gibt es harte Schatten und, wenn man zwei Quellen verwendet, einfach nur harte Schatten, die sich überlagern und nicht mehr ganz so dunkel wirken. Die harten Grenzen der Schatten gelten meist als unschön, man beseitigt sie, indem man die effektiv leuchtenden Flächen größer macht – mit Reflektoren, Schirmchen und Softboxen. Stellt man eine runde Softbox von 2 m Durchmesser 1 m vor einem Objekt auf, kommt das Licht nicht nur gerade von vorn, sondern auch aus bis zu 45° von rechts, links, oben, unten und allen Richtungen dazwischen. Vom Objekt aus gesehen hat man einen Öffnungswinkel von 90°. Die gleiche Lichtquelle 5 m entfernt gibt einen Öffnungswinkel von nur noch 22°, die Schatten werden wieder härter.
Eine Softbox mit Reflektor als Aufheller
Portraitaufnahmen habe ich schon recht erfolgreich mit nur einer Softbox gemacht. Ich würde den Öffnungswinkel dabei auf etwa 30° – 45° schätzen. Das sollte bei Makros auch machbar sein. Alleine die Fläche des Aufsteckblitzes, auch mit ausgeklappter Streuscheibe, wäre etwas klein, aber hätte ich eine kleine Softbox von 10 – 20 cm Durchmesser und könnte die ca. 20-30 cm entfernt von meinen Motiven platzieren, dann würde das reichen.
Im Zubehörhandel habe ich dann einen Schwanenhals zum Aufstecken auf den Blitzschuh der Kamera und eine Mini-Softbox gefunden. Das sieht so aus:
Die Konstruktion ist zwar etwas unhandlich, aber mit etwas Übung zweihändig durchaus kontrollierbar. Ich bin mit den Ergebnissen recht zufrieden. Nur an der Positionierung des Blitzes muss ich noch etwas Herumprobieren, das Licht kommt jetzt noch etwas zu sehr von der Seite.
Mit einem einfachen Trick eine deutsche Tastaturbelegung mit englischem Lightroom benutzen.
Die Herausforderung
Weil ich bevorzugt englischsprachige Fotoseiten lese und auch eine Menge Foto-Lehrbücher in dieser Sprache besitze, bevorzuge ich ein englisches Lightroom. So spare ich mir die Suche nach der deutschen Bezeichnung für einen Begriff, der z. B. in einer Anleitung verwendet wird. Bei Photoshop halte ich es genau so, doch darum soll es hier heute nicht gehen.
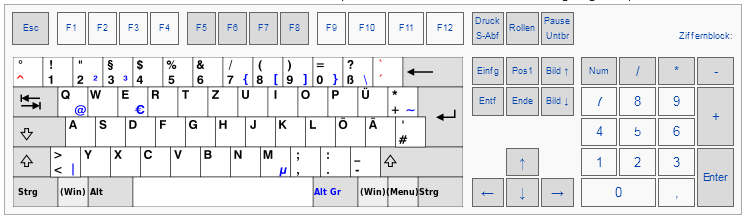
Die Herausforderung ist, dass Adobe leider mit dem Sprachwechsel auch die Tastaturbelegung wechselt. Es ist nicht vorgesehen, ein Tastaturlayout separat einzustellen. Tasten, die auf einem englischen Layout bequem sind, liegen auf der deutschen Tastatur unmöglich. Zum Beispiel der Backslash „\“ oder die eckigen Klammern „[“ und „]“. Sie liegen in der US-Version direkt nebeneinander und sind ohne Kombination mit anderen Tasten erreichbar:
„KB United States-NoAltGr“ von Diese Datei wurde von diesem Werk abgeleitet: KB United States.svg. Lizenziert unter CC BY-SA 3.0 über Wikimedia Commons – https://commons.wikimedia.org/wiki/File:KB_United_States-NoAltGr.svg#/media/File:KB_United_States-NoAltGr.svg
Für uns Deutsche sieht das anders aus, alle drei Tasten sind nur per Kombination mit Alt Gr erreichbar.
Quelle: Wikipedia
Die „Lösung“
Bei einem Sprachwechsel wird in Lightroom auf eine andere Sprachressourcedatei umgestellt. Die Datei für Deutsch ist bei einer Installation von Lightroom Classic CC zu finden (unter Windows, hab leider keinen Mac zum Testen): %Program Files%\Adobe\Adobe Lightroom Classic CC\Resources\de\TranslatedStrings_Lr_de_DE.txt.
Es gibt erwartungsgemäß keinen Ordner und keine Datei für die Sprache Englisch (en). Interessant ist aber, dass diese, wenn es sie gibt, berücksichtigt werden. Das kann man leicht ausprobieren, indem man den Ordner …\Resources\de kopiert und in …\Resources\en umbenennt, die Datei TranslatedStrings_Lr_de_DE.txt zu TranslatedStrings_Lr_en_US.txt umbenennt und danach eine englische Version Lightroom startet. Es werden jetzt nicht nur die deutschen Anzeigetexte verwendet, sondern auch die Tastaturbelegung.
Die Datei selber ist eine reine Textdatei. Hier mal ein Auszug aus dem Inhalt:
Die rot hervorgehobenen Zeilen sind interessant. Es werden offensichtlich Tastaturbelegungen vorgenommen. Was liegt also näher als alle Zeilen, die nichts mit Tastaturbelegungen zu tun haben, aus der Datei zu werfen und diese dann für das englische Lightroom zu verwenden? Nichts, genau so funktioniert es.
Bei Bedarf lassen sich dann gleich noch ein paar unglücklich gewählte Belegungen korrigieren und ein paar wenige Texte anpassen, fertig ist die eigene Tastaturbelegung für deutsche Tasten an englischem Lightroom.
Umsetzung
Einen Download einer fertigen Datei möchte ich an dieser Stelle nicht abieten, weil
ich meine persönlichen Vorlieben in meine eingebaut habe, die nicht jeder teilen mag,
die Datei von der Version von Lightroom abhängen dürfte und
ich nicht sicher bin, wie begeistert Adobe wäre.
Löschen überflüssiger Zeilen mit Notepad++.
Ich will nicht die deutschen Texte, sondern nur die Tastaturbelegung. Also müssen alle Zeilen raus, die nichts damit zu tun haben. Man kann das Löschen von nicht benötigten Zeilen mit Suchen und Ersetzen mit regulären Ausdrücken deutlich erleichtern. Ich habe alle Textteile mit notepad++ gelöscht, auf die folgender Ausdruck passte:
Es gibt einige verbliebene Zeilen, die deutsche Begriffe enthalten, die der Anzeige der aktuellen Tastenbelegungen auf dem Hilfeschirm, den man mit Strg+< erreicht, dienen. Es erscheint mir sinnvoll, die hier auftauchenden deutschen Begriffe durch die englischen zu ersetzen, also:
Command statt Befehl
Delete statt Löschen
Option statt Wahl
Enter statt Eingabe
Backspace statt Rücktaste
Shift statt Umschalt
Right Arrow statt Nach-rechts-Taste
Left Arrow statt Nach-links-Taste
Up Arrow statt Nach-oben-Taste
Down Arrow statt Nach-unten-Taste
Ctrl statt Strg
Tab statt Tabulatortaste
Space statt Leertaste
Abschließend
Danach ist die Anzahl der Zeilen, die man manuell löschen muss, überschaubar. Man findet sie leicht beim Durchscrollen, und man kann ja auch rasch korrigieren, wenn man dann doch einen vergessenen deutschen Text in der Lightroom-Oberfläche findet.
Natürlich braucht man immer noch nicht wirklich alle verbleibenden Zeilen aus der Datei. Da, wo die englische Originalbelegung gut funktioniert, muss man nicht korrigierend eingreifen. Es ist viel einfacher, alle Zuordnungen aus der deutschen Datei zu übernehmen, als mühselig herauszusuchen, welche man braucht.
Wenn man will, kann man jetzt noch Belegungen anpassen. Aktuell gibt es aber für meinen Geschmack gar nicht mehr viel zu tun, die echten Fehler sind inzwischen behoben, nur ein paar Anzeigen auf den Hilfeschirmen passen noch nicht so ganz. Kann man machen, muss man nicht.
Aktueller Stand
Zum Schluss noch meine aktuellen „Korrekturen“ für Lightroom Classic CC 7.2:
„$$$/AgDevelopShortcuts/Create_Virtual_Copy/Key=Command + T“
„$$$/AgDevelopShortcuts/Rotate_left/Key=Command + ,“
„$$$/AgDevelopShortcuts/Rotate_right/Key=Command + .“
„$$$/AgLibrary/Help/Shortcuts/HideShowFilterBarKey=<“
„$$$/AgLibrary/Help/Shortcuts/Mac/HideShowFilterBarKey=<“
„$$$/AgLibrary/Bezel/FilterBarHidden=Press < to show the filter bar again“
„$$$/AgLibrary/Bezel/Mac/FilterBarHidden=Press < to show the filter bar again“
„$$$/AgLocation/Bezel/Filterbar/FilterBarHidden=Press < to show the filter bar again“
„$$$/AgLocation/Bezel/Filterbar/Mac/FilterBarHidden=Press < to show the filter bar again“
„$$$/Slideshow/Bezel/HeaderHidden=Press < to show the header bar again“
„$$$/Slideshow/Bezel/Mac/HeaderHidden=Press < to show the header bar again“
Soft Light ist die Verrechnungsmethode, über die man am häufigsten Fehlerhaftes liest. Was auch daran liegt, dass verschiedene Hersteller die Methode unterschiedlich definieren und so zur Verwirrung beitragen. Ich habe leider noch keine Begründungen für die Wahl der jeweiligen Berechnungen gefunden. (mehr …)