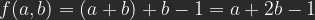Recently I found an interesting article on frequency separation on the Fstoppers’ pages that made me curious about this method. Seems to be pretty much standard now for beauty retouching. I learned something, but the article left me with unsanswered questions:
Why is Linear Light the correct blend mode for rejoining the two layers created during frequency separation?
What exactly is the difference between addition and subtraction blend mode?
Why should there be a difference in the process depending on the colour-depth (8-bit versus 16-bit)?
So I decided to have a closer look. But first, I had to understand Blend Modes in general. Might be worth starting there if you have never dealt with the subject before.
The Task
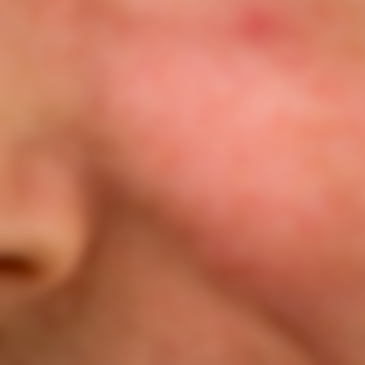
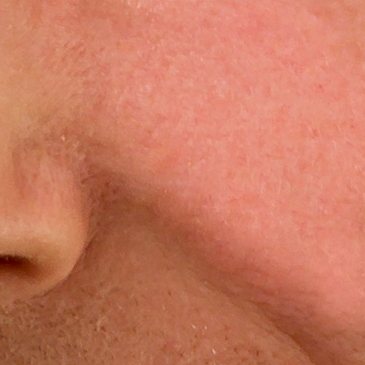
We want to split one image into two such that one of the resulting images only contains fine detail, the other the large scale changes in colour and brightness. Take the following crop from a portrait as an example:
You can see pores, a light stubble, skin texture, and you can discern features like part of a nose, a line, shadows. Here the skin texture should end up in the first image, colours and larger shadows defining the shape in the second. Later on I’d like to combine the two images again in a way that we – unless we manipulated one of the images – get the original back.
“Why?”, you may ask. Simply because after this so called frequency separation you can retouch skin-tones without having to worry about the texture and vice versa. If I wanted to get rid of the red spot you can see top right, I’d just correct the colour and brightness and leave the texture alone. All the unmodified areas will, once blended again, look unchanged. The manipulated area will look very natural. So that’s why, I’ll show you how.
But before we start, some (very little) theory.
Frequencies
Fine structures mean spatially rapid changes of brightness, or a strong local contrast. You can interpret the changes of brightness as a superposition of waves. Waves, you may remember from your physics lessons, have a frequency, in this case a spatial frequency. Fine structure means high frequency, changes over a larger distance means low frequency.
Frequency Filtering
If you are an audiophile, you may have heard of high-pass or low-pass filters used in audio equipment. They do what their names say, the low-pass lets the low frequencies pass, i.e. the bass notes, while the high-pass does the same for high frequencies. For the latter, we indeed have a ready-made filter in Photoshop. It lets the high frequencies of an image pass and blocks the low frequencies yielding an image wich is mostly grey, close to 50 %, with little deviations on a small scale. You can control the scale – or as the audiophile might say, the cutoff frequency – with the radius parameter.
Photoshop also knows low-pass filters, only they are called differently. You may be able to identify them yourself. What evens out all the small scale changes? Blurring does. There are several blur filters available. For our purpose it does not really matter which one we choose, though you have to be careful with filters like surface blur or smart blur, as they tend to create sharp edges, which mean high frequency again. I personally would use the good old workhorse gaussian blur with a rather large radius.
Back to the Task – Splitting the Image
First we have an Image A. We create two copies and modify one so we get a new image B that is different from the original A. In this example I used a gaussian blur with a radius of 6 pixels:
You see, all the fine structure is gone, no skin texture to speak of left.
Now I want to create another image C from the second copy that contains only the differences between original A and B. Should be easy, just take the second copy and use the Apply Image command of Photoshop with the blend mode Subtract with A as target and B as source and be happy. Unfortunately there is a catch.
Photoshop only allows values between 0 and 1 as result, everything below 0 and above 1 gets cut off. Not a very good idea when subtracting two very similar images, there will almost certainly be some pixels with values below 0. So what we actually do is:
divide by 2
add ½
Thus the complete information is kept. The following formula is for a pixel-value of C:
.
It is easy to see that nothingis lost when you look at the extremes, i.e. combinations of .
Btw, I am showing all this for one channel only, for an RGB image this can be done for each channel separately.
The result of the “subtraction” is quite similar to that of Photoshop’s own High Pass filter – not exactly surprising.
Note
Photoshop can handle images with a depth of 8-bit, 16-bit or even 32-bit per pixel. The 1 I talked about above correspondes to 255, 65536 or 4294967295 respectively. The apply image dialogue offers two paramerters for the blend mode subtraction, scale and offset. For our intention we need 2 for scale – that is for the aforementioned division by two, and 128 for offset. Bit hard to recognise the addition of ½, but that is what it is. Regardless of the bit depth the offset has to be specified in parts of 256, and 128 divided by 256 happens to be ½. This is confusing, and probably the reason for some more complicated workflows I have seen.
One mentioned frequently is this (for 16-bit images):
invert image B
add the result to A
set the scale-parameter to 2 (i. e. divide by 2)
Looking at the math I wasn’t able to find any difference to my method. My practical tests didn’t show any either, neither for 8-bit nor for 16-bit images. If you know that inversion just means subtracting the pixel value from 1, the formula is easy:
.
So the answer to question three is: there is no difference.
Reassembly
Now we just need another blend mode that can reassemble the two images B and C so that, if both are unchanged, we get A again. Simply adding the pixel-values won’t work of course, we scaled and shifted the result of the subtraction. So we need to find the reverse operation. So we subtract ½ from C, multiply the result by 2 and add B.
.
Surprisingly this is exactly the formula for the Linear Light blend mode. So my first question is answered as well: Linear Light is the reverse of Subtraction.
Using the Frequency Separation Technique
In practice you will of course not use Apply Image to join the hard-won separate images immediately again. You will instead use both images as layers, C over B, and set the blend mode for C to Linear Light. So you keep two layers you can work on separately. Of course you can add layers between the two, for example for non-destructive retouching. In the example I was able to remove the red spot while keeping the texture. Retouching is not within the scope of this article.
The remaining answer to question two you will find in my little series on Blend Modes – with more math and simulations.
I hope you liked my little excursus on frequency separation. If you have questions or find mistakes, do not hesitate to leave a comment.
I tried to figure out the frequency separation method for retouching portraits. Initially I didn’t really understand why which step was used. So I first had to dig deeper into the Photoshop (PS) blend modes. There’s a lot you can find on the internet regarding blend modes. Not everything I found was correct, let alone understandable for me. Especially photographers and PS users approach the subject rather intuitively, not many try to understand the math behind the tools they apply. Though that would help predicting the effects that can be achieved.
So I decided to find out what exactly happens with the goal to write a concise, but not too complicated explanation myself. The first surprise during my research was that not everybody (not even the graphic software vendors) mean the same when they talk about soft light for example. Adobe is undisputedly one of the leaders on the market, but in PS in particular some of the blend modes are implemented not really well (my humble opinion, of course).
The Task
Calculate a new image from two existing.
This is always used when you place two layers above each other in PS. The simplest, but also most boring blend mode, is making the upper layer opaque so you see nothing of the lower layer. You can use other blend modes to manipulate colours and luminosity of the lower source by the upper source (yes, in some cases the order is important, like with an opaque layer). That is what photographers use blend modes for.
Assumptions, Simplifications and Definitions
Assumption: the the value for a particular pixel of the new image (the target) can be deduced from the values of the corresponding pixels (same position, i. e. same coordinates) of the two source images.
Simplification: all I present I only show for luminosity or rather black and white images with just one channel. The same holds for RGB images with three separate channels, on just uses the same formulas thrice, they are not influencing each other. Transparency (alpha-channel) shall be ignored for now as well.
I will call the source images A and B, das target image C. If you are thinking layers, think A the lower layer, B the upper. C is what PS displays on the screen.
I shall use a common orthogonal coordinate system defined by counting pixel columns and rows from the lower left corner. The location of any pixel is precisely defined by its coordinates .
Let be the value (luminosity) of a pixel of image A, the value for a pixel of B with the same coordinates. As a result of a calculation you get a pixel-value of C: .
For better readability I will leave out the coordinates, at least as long as no pixels with differring coordinates are involved in the calculatation.
Pixel-values will always be given in numbers between (zero) for black and (one) for white, regardless of the actual bit depth. When calculating , you have to keep in mind that its value also is restricted to this interval.
You will immediately see a difficulty: there are plenty of ways to combine 0 and 1 by a formula that gives values outside this interval. PS solves this problem by truncating the exceeding values. Anything below 0 or above 1 is ignored. That has some nasty consequences whenever you try to do several calculation steps in sequence. Part of the information is lost. You can not calculate in PS by executing and this, though it seems mathematically correct to do so.
Visualisation
To visualise the results I use two images as a basis for all blends. These contain values linear from 0 to 1, once from left to right (, defines a horizontal axis for a from 0 to 1), once from bottom to top (, the vertical axis from 0 to 1). This makes sure the result contains all possible combinations and we will see how smooth transitions are.
Image AImage B
Blend Modes
To begin with I’ll have a look at some simple, but not trivial methods, multiplication and addition, then a combination of both and finally a version that uses two different formulas depending on the pixel-values of B. Further blend modes I will explain in the next part of this series.
Multiply
Multiplication is one of the simplest blends, because the function does not give any values outside the allowed interval or 0 to 1. By the way, PS indeed uses multiplication, not the geometric mean, though the latter might seem more plausible.
Results for a and b between 0 and 1 lie within that interval as well.
For my test images you get:
Looking at the result you can see that two edges and hence three of the corners should be black, because a multiplication with 0 always yields 0. Only in the top right corner you get a value of 1 for white.
Multipy
Aside: Geometric Mean (not available in Photoshop)
For me the geometric mean
seems to be the better option. There’d be a nice linear transition along the diagonal.
Linear Dodge
Linear Dodge is the name given to the addition. It is immediately clear that an addition of two numbers between 0 and 1 yealds results between 0 and 2. For half of the pixels the results get truncated to 1. Used on photos, this can easily lead to burnt out areas.
If the sum a+b gets larger then 1, it is replaced by 1. The formula never gives results below 0 anyway, so no truncating there. Hence you’d expect white on and above the diagonal between top left and bottom right, below that a linear gradient down to black in the bottom left corner.
Linear Dodge
Linear Burn
This is the negative inverse of linear dodge. It is the same as problematic on photos, you might get fully black areas.
If the sum a+b gets less then 1, f is replaced by 0. Values above 1 are never reached anyway, no truncating. Hence you’d expect black on and below the diagonal between top left and bottom right, above that a linear gradient up to white in the top right corner.
Linear Burn
Linear Light
Frequently you will find linear light described as a combination of linear dodge for and linear burn for . Not quite right, but close. If for you compress the formula for linear dodge on the b-axis by a factor 2 and shift it up that axis by 1/2, and then also compress the one for linear burn for by a factor 2 on the b-axis, you indeed get:
Or, by resolving the terms, simply:
This is no longer commutative in a and b. Swapping the images A and B will yield a different resulting C.
Along the left edge (a=0) you expect black from the bottom up to b=0.5, then a linear transition to white. On the bottom edge (b=0) just black, because the -1 makes sure all possible results are negative. For b= 1 you get white on the top edge. On the right edge (a=1) you get from b=0 to b=0.5 a linear transition from black to white, above that just white.
Lineares Licht
Of interest for the PS user is the fact that an image B with for all pixels transfers image A unchanged to C when combined with this blend mode. is 50 % grey, which is called the neutral colour for linear light. Linear light is often used to manipulate a photo by using an almost grey layer with only minimal deviations, for example in high-pass sharpening or as one step of the frequency separation method.
Linear light can be described as the sequential execution of linear dodge and linear burn (with B multiplied by 2) or as linear burn with doubled B. The latter unfortunately cannot be recreated in PS, as it would need multiple steps, one of them yielding results outside the allowed interval. Intermediate results would be truncated, the main result would be wrong.
Vincent Versace, dessen Buch Welcome to Oz 2.0 ich gerade durcharbeite, ist ein großer Freund von vorgefertigten Effekten, z.B. von Nik (jetzt leider Google) oder OnOne. Ich habe bislang immer Abstand genommen von diesen Dingen, weil mir die Ergebnisse immer zu spektakelig daher kamen. Jetzt habe ich probehalber mal angefangen, damit zu spielen. Noch bin ich unbegeistert. Viele der Effekte sehen aus wie Instagram quadriert. Ich kann sehr schnell Bilder produzieren, die so aussehen wie viele andere auch. Eine Art moderner Pseudo-Retro Look mit Pseudo-Analogfilm-Anmutung, Pseudo-Cross-Processing abgerundet mit einem Pseudo-Glasnegativ-Grunge-Rahmen.
Gefällt mir das? Nein! Ich frage mich natürlich, warum mir das nicht gefällt. Weil es so aussieht wie vieles? Nicht wirklich. Es gibt so viele Photographen, da ist es schwer, immer was Originelles zu produzieren, was noch nie da war. Ich denke, es liegt daran, dass man die Effekte so deutlich sieht. Es ist zu einfach, niemand muss sich die Mühe machen, lange an einem Bild zu arbeiten. Nun bedeutet langes Arbeiten natürlich noch lange nicht hohe Qualität. Aber es bewirkt, dass man gezwungen ist, sich länger mit dem Objekt zu beschäftigen, mehr nachzudenken – auch mehr über das Warum und Was, nicht nur über das Wie.
Alles in allem sind die Werkzeuge vermutlich nützlich und gut, wenn in der richtigen Dosierung eingesetzt. Also dann, wenn ich verstanden habe, warum ich einen Effekt haben will, wenn ich ihn einsetze, weil ich eine Idee habe, und wenn ich der Versuchung widerstanden haben, den Effekt einfach nur deswegen zu verwenden, weil es ihn gibt. Und die Versuchung ist groß: Foto oben rein, ein halbes Dutzend Effekte ausprobiert, sieht geil aus, Rahmen drum und ab auf facebook. Je weniger geplant das Bild aussieht, desto Kunst. Mein Ansatz ist das nicht. Ich werde mir die Effekte dennoch etwas genauer ansehen, vielleicht ist etwas dabei, was ich brauchen kann. Vielleicht spare ich in dem einen oder anderen Fall eine mühevolle Maskenerstellung, wenn die Kontrollpunkte von Nik Effects das gleiche erreichen. Vielleicht, wenn ich es brauchen kann und es zum Bild passt.
Das gilt natürlich auch für alle Spielereien, die ich in LightRoom und Photoshop schon ohne Plug-In kann. Ist es eine gute Idee, einer Digitalaufnahme ein künstliches Filmkorn hinzuzufügen? Warum soll man eine Schwäche der alten Filme imitieren? Was tut man dabei eigentlich? Man imitiert eine Ästhetik. Das gleiche gilt für Cross-Processing und, wenn man noch weiter gehen will, auch für schwarz-weiß Aufnahmen. Bitte nicht falsch verstehen: ich verdamme nicht etwas die Schwarz-Weiß-Photographie. Aber man muss sich klar darüber sein, was man da tut. Wie stützt die Entscheidung das Bild? Setze ich die künstliche Vignette ein, weil sie so schön historisch wirkt und damit das Bild älter ( = wertiger) wirken lässt oder weil ich damit den Blick ins Zentrum lenken und ein wenig von der strengen Rechteckigkeit des Formats aufheben kann?
Wir sollten und als Digitalphotographen nicht minderwertig fühlen und der guten alten Zeit hinterherhecheln. Und wenn wir wirklich den Look eines Analogfilmes wollen, dann sollten wir analog arbeiten und die Dunkelkammer wieder rauskramen. Für mich bleibt ein Foto mit fiesem Grün-Gelbstich ein Foto mit Grün-Gelbstich. Ich war in den 70ern schon auf der Welt, ich brauch das nicht als Retro-Look.
Ich lese gerade ein Buch von Vincent Versace namens Welcome to Oz 2.0. Schon das erste Kapitel hat mich mächtig zum Grübeln gebracht. Ich mag seinen Ansatz, das sorgfältige Vorgehen. Er macht erst einen Plan, stellt sich die Frage, warum er etwas tut, was er erreichen will, bevor er den großen Werkzeugkasten herausholt. Mit seiner Art der Farbstichkorrektur bin ich aber gar nicht einverstanden. Also habe ich mir das mal genauer angesehen und versucht, zu verstehen, was Photoshop wie tut und wie man das einsetzen kann.
Meine Erkenntnisse kann man am einfachsten an einem simplen Beispiel nachvollziehen. Ein Photo ist herzlich ungeeignet, also habe ich mal etwas vorbereitet. In dem folgenden Beispielbild sieht man zwei Reihen Kreise. Die zweite Reihe ist das Original, der ersten Reihe wurde ein Farbstich gegeben und der Kontrast wurde reduziert. Aufgabenstellung ist nun, zu versuchen, mit Hilfe von Photoshop Gradationskurven das Bild möglichst nahe an das Original zu bringen. Insofern ist die zweite Reihe auch das Ziel, da will ich hin. Die Originalkreise haben Grauwerte von 3%, 27%, 50%, 73% und 97%. Der Hintergrund ist 50% Grau, weshalb auch der mittlere Kreis in der zweiten Reihe verschwindet.
Meine Aufgabenstellung
Die Chancen für eine erfolgreiche Korrektur sind gut: ich weiß etwas über das Bild, das ich korrigieren soll, ich habe eine Referenz. Das ist wichtig, denn ansonsten bleibt eigentlich nur das Erraten des Zieles.
Messen
Irgendwo muss man anfangen. Ich fange an, indem ich daran glaube, dass mein Monitor gut kalibriert ist und einen gleichförmigen Grauverlauf zeigt, dass also das, was ich als RGB Werte der einzelnen Pixel messen kann, auch dem entspricht, was ich sehe. Letztendlich ist das aber auch egal, denn bei dem, was die Werkzeuge tun, geht es nur um die Werte, nicht um das, was ich sehe.
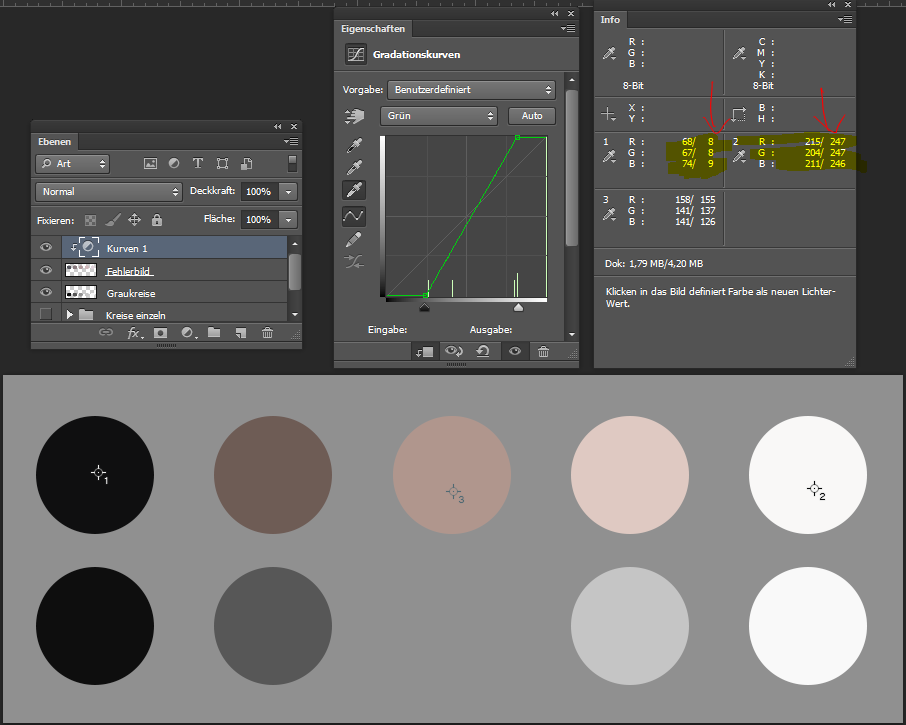
Also fange ich mit dem Messen an. Ich setze mit dem Pipetten-Werkzeug drei Farbmesspunkte. Dazu klicke ich mit gehaltener Umschalt-Taste auf die gewünschten Stellen.
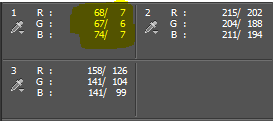
Es ist zu erkennen, dass die Messwerte noch deutlich von den Zielwerten 3% Grau, 97% Grau und 50% Grau abweichen. Die gesetzten Messpunkte werden mir dazu dienen, meine Arbeit bei der Korrektur zu überprüfen.
Eine Anmerkung an dieser Stelle: eigentlich mache ich hier schon den ersten Fehler, denn ich überprüfe nur drei Stellen, in der stillschweigenden Hoffnung, das die Farb- und Helligkeitsfehler keiner allzu wilden Verteilung folgen. Bei realen Aufnahmen von modernen Digitalkameras kann man das üblicherweise voraussetzen, ohne allzu weit daneben zu liegen.
Schwarzpunkt
Zunächst soll der Schwarzpunkt korrigiert werden. Dazu lege ich eine Korrekturebene über die bestehenden Ebenen. Ich wähle die Gradationskurven, beschränke die Korrekturen gleich auf die darunterliegende Ebene, die mein Fehlerbild enthält, damit Hintergrund und Zielbild nicht beeinflusst werden.
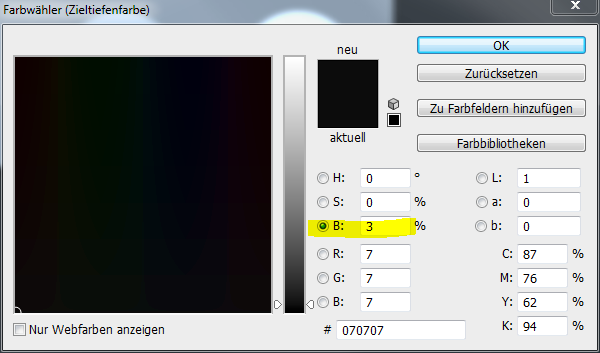
Nun prüfe ich als erstes den Zielwert für den Schwarzpunkt, die sogenannte Zieltiefenfarbe. Dazu mache ich einen Doppelklick auf das oberste der drei Pipetten-Symbole.
Das Ziel ist eingestellt auf 3% Grau, passt perfekt. Das Fenster kann wieder geschlossen werden.
Jetzt verwende ich die Umschalt-Feststellen-Taste, um meinen Mauszeiger in ein Fadenkreuz zu verwandeln, wähle mit einem Einfachklick die obere Pipette aus. Mit einem Rechtsklick ins Bild öffne ich das Kontextmenü, mit dem man die Größe der Pipettenspitze auswählen kann. Da echte Bilder fast immer ein leichtes Rauschen enthalten, halte ich es für sinnvoll, mehr als ein Pixel aufzunehmen und daraus den Mittelwert zu bilden, ich wähle daher den 3×3 Pixel Durchschnitt.
Nun klicke ich einmal möglichst genau auf meinen Farbmesspunkt 1. Hier in diesem Fall hätte es natürlich gereicht, irgendwo in den Farbkreis zu klicken. Bei Fotos sind die Farbflächen jedoch meist nicht so schön groß und gleichförmig, da sollte man dann schon den vorher mühsam herausgesuchten Messpunkt genau treffen. Dabei hilft der Fadenkreuz-Mauszeiger.
Das Ergebnis ist ein schöner schwarzer Kreis, wie gewünscht. Interessanterweise zeigen die Messwerte, dass das Ziel von 3% (entspricht RGB 070707) nicht ganz getroffen wurde.
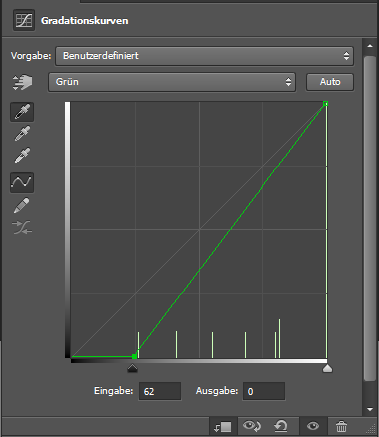
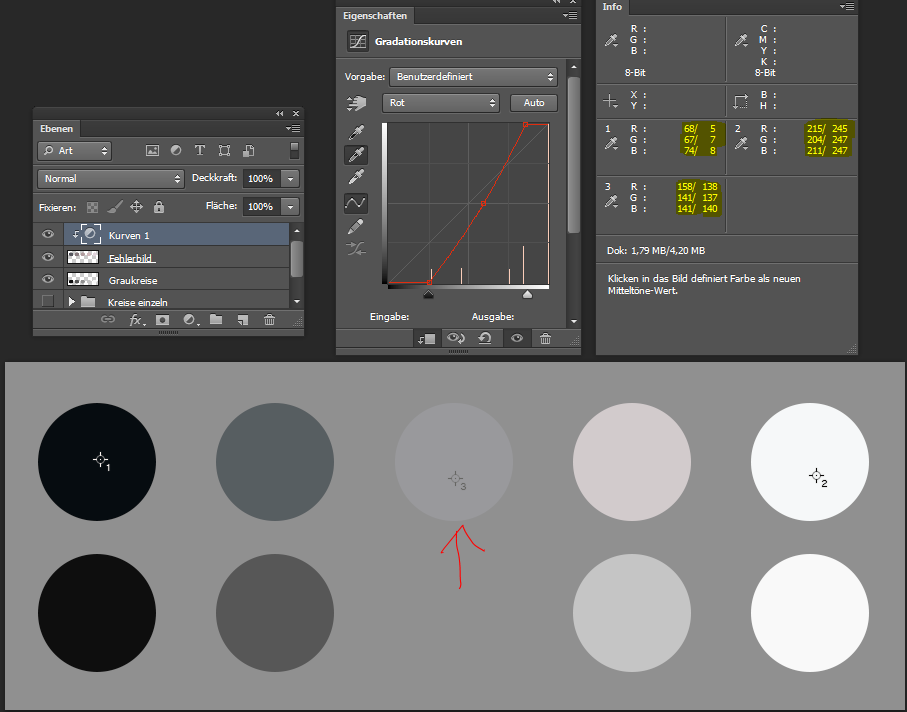
Warum wird klar, wenn man sich ansieht, was das Schwarzpunkt-Werkzeug getan hat. Dazu sehe ich mir die Kurven genauer an.
Die weiße Linie steht für die RGB-Summe, hier hat sich nichts geändert, aber bei den Linien für die einzelnen Farben Rot, Grün und Blau. Hier sind die Fußpunkte unterschiedlich weit nach rechts verschoben worden. Die Linien selber sind weiterhin gerade, haben aber in Folge eine stärkere Steigung. Was heißt das?
Die Linien stehen für eine Übersetzung eines alten Wertes (horizontale Achse) in einen neuen Wert (vertikale Achse). Alle Werte im Originalbild zwischen 0 und dem Fußpunktwert werden auf 0 abgebildet, alle darüber auf neue Werte größer 0. Betrachten wir den Wert für Rot für den linken Kreis. Der alte Wert war 68, der neue ist 7, wie gewünscht. Die Übersetzung erfolgt im Prinzip so, dass man auf der horizontalen Achse zur 68 geht, dann nach oben zur roten Linie, dann nach links zur vertikalen Achse und dort den neuen Wert 7 abliest. Wenn man den Mauszeiger über den Kurven schweben lässt, kann man die Werte als „Eingabe“ und „Ausgabe“ anzeigen lassen.
Bei Grün passt die Übersetzung nicht optimal. Das liegt daran, dass man den Fußpunkt, wenn man mit 8bit Kurvenanzeige arbeitet, nicht genau genug verschieben kann, um den Punkt (67,6) mit der grünen Linie zu treffen. Ich versuche es noch mal, um zu zeigen, was ich meine. Dazu schalte ich um auf die Grün-Kurve, markiere den Fußpunkt mit einem Mausklick und versuche, ich mit den Pfeiltasten so zu schieben, dass mein Messpunkt für Grün auch 7 meldet.
Das gelingt mir leider nicht, ich erreiche wegen der erzwungenen Ganzzahligkeit des Eingabewertes nur entweder 6 oder 8.
Was habe ich gelernt:
Die Schwarzpunkt-Pipette verschiebt den Fußpunkt der Gradationskurve für jede Farbe einzeln so, dass bei der Übersetzung mit den entstehenden Kurven die gewünschten Zielwerte für meine angeklickten Quellwerte möglichst genau getroffen werden.
Der Fußpunkt legt den höchsten Quellwert fest, dem noch der Zielwert 0 zugewiesen wird. Das ist nicht der Punkt, der sich aus den gemessenen Quellwerten und festgelegten Zielwerten ergibt, also nicht der angestrebte 3% Grau-Wert.
Auch wenn ich den Zielwert für meinen Schwarzpunkt auf 3% Grau festgelegt habe, heißt das nicht, dass es im Bild nicht noch dunklere Punkte geben kann, die aber noch nicht vollständig schwarz sein müssen. Findet sich z.B. ein Punkt, der für Rot den Wert 64 hat, dann wird dieser den Zielwert 2 erhalten, nicht 0.
Wenn mein Originalbild Punkte mit Quellwerten unterhalb des Fußpunktes enthält, dann werden diese alle auf 0 gesetzt. Wenn es sich nur um einzelne Punkte oder kleine Flächen handelt, ist das vergleichsweise egal. In der Praxis heißt das aber meist, dass sich unschöne zusammenhängende Flächen bilden, die alle den Wert 0 haben. Man kann keine Details mehr erkennen, keine Struktur, keine sogenannte „Zeichnung“, Diese Stellen bezeichnet man als „abgesoffen“.
Im Idealfall sind alle dunklen Flächen „durchgezeichnet“, das heißt, man kann überall noch Strukturen erkennen. Das ist auch der Grund, warum ich als Zielwert für den Schwarzpunkt 3% Grau und nicht echtes Schwarz gewählt habe: ich verschaffe mir eine Reserve, die verhindert, dass später z.B. beim Druck die Tiefen nicht „zulaufen“.
Anmerkung dazu: ich halte es in Abhängigkeit vom Inhalt des Bildes für durchaus in Ordnung, schwarze Flächen zu erzeugen. Wo kein Licht ist, kommt auch keins her. Die Entscheidung, ob man das macht oder nicht, muss man für jedes Bild treffen. Da, wo man Zeichnung haben will, da sollte es halt nicht nur schwarz sein.
Weißpunkt
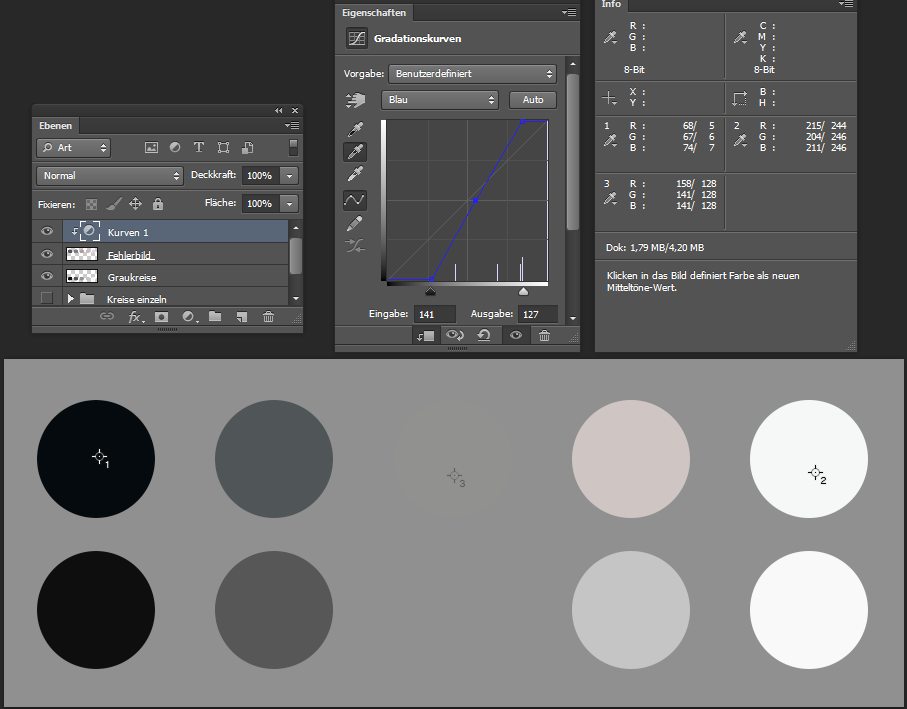
Im nächsten Schritt mache ich analoge mit dem Weißpunkt weiter. Ich lege den Zielwert auf 97% Grau fest, klicke dann mit der Weißpunkt-Pipette in den rechten Kreis, der sofort weiß erscheint.
Auch hier wird der Zielwert nicht exakt getroffen, aber ich bin nah dran. Bemerkenswert ist, dass sich die Messwerte für das schwarze Feld verändert haben. Das ist so, weil der Schwarzpunkt kein Ankerpunkt der Kurve ist. Beim Einstellen des Schwarzpunktes wurde der Fußpunkt verschoben, so dass der gewünschte Schwarzpunkt, oder besser 3%-Grau-Punkt, auf der Kurve zu liegen kommt. Nun wird auch noch der Kopfpunkt so verschoben, dass der Weißpunkt getroffen wird. Ergebnis: die Kurve wird steiler. Sie beginnt aber immer noch beim selben Fußpunkt, muss also den alten Schwarzpunkt verfehlen.
Das kann dazu führen, dass man sich einen neuen Farbstich einschleppt. Zum Glück kann ich leicht korrigieren indem ich den Vorgang für den Schwarzpunkt einfach noch mal ausführe. Der Fußpunkt wird noch mal angepasst, allerdings ist die Änderung an der Kurve diesmal so gering, dass sich für den Weißpunkt nichts mehr groß ändert.
Als Ergebnis sind die äußeren Kreise optimal korrigiert, mit dem bloßen Auge vom Original nicht mehr zu unterscheiden. Die Grautöne dazwischen leider sind noch nicht so schick.
Mitteltöne
Jetzt kommt die letzte Pipette zum Einsatz, die für die Mitteltöne. Sie funktioniert anders als die beiden anderen. Bei Weiß- und Schwarzpunkt werden Helligkeit, Sättigung und Farbton der Quelle in die des Zieles übersetzt, bei den Mitteltönen spielt die Helligkeit der Quelle keine Rolle, nur Farbton und Sättigung. Da ich aber den Farbstich der Mittelwerte korrigieren will und nicht den der Tiefen oder Lichter messen, verwende ich am Besten eine Quelle, die korrigiert möglichst ein neutrales Mittelgrau haben soll. Es ist nicht entscheidend, welche Farbe diese Stelle in der farbstichigen Aufnahme hat, wichtig ist, dass sie in Natura neutral grau war. Im Beispiel ist das der mittlere Kreis.
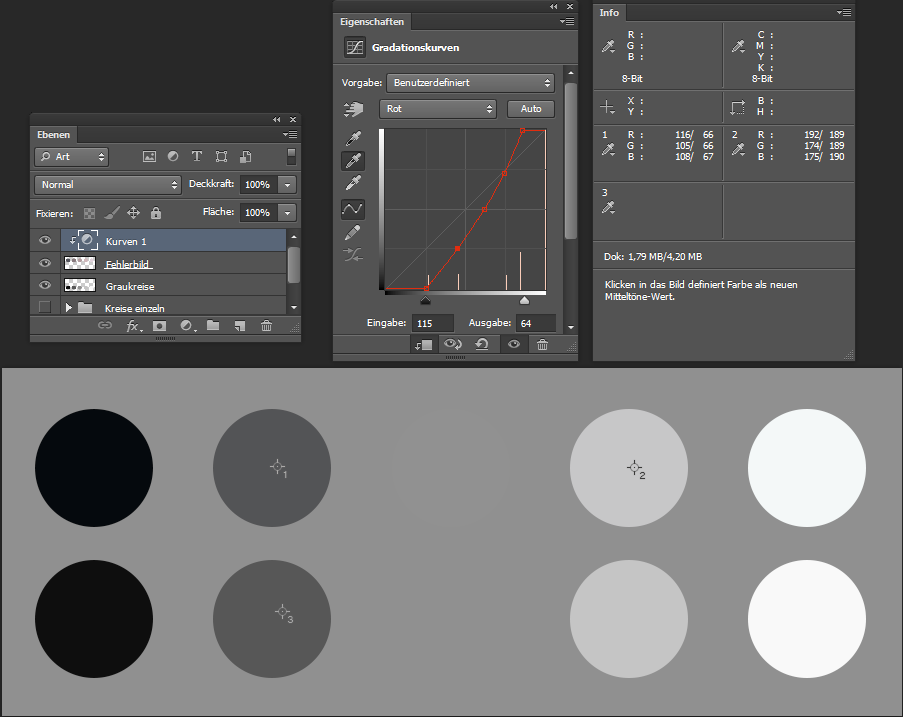
Ich kontrolliere sicherheitshalber noch mal den Zielwert, der sollte hier ein 50% Grau sein, und klicke dann mit der Mittelwert-Pipette in den mittleren Kreis. Das Ergebnis ist zunächst überraschend.
Was fällt auf:
man kann den mittleren Kreis noch sehen. Wenn er wirklich auf Mittelgrau korrigiert worden wäre, müsste er auf dem Hintergrund verschwinden.
Die Werte des dritten Messpunktes sind alle deutlich größer als 128 und deutlich unterschiedlich.
Die beiden Kreise rechts und links der Mitte haben immer noch einen Farbstich, wenn auch weniger als vorher.
Die Werte der Messpunkte 1 und 2 haben sich auch noch mal geändert.
Es ist einfach zu verstehen, was jetzt passiert ist. Kopf- und Fußpunkte der Kurven sind fest geblieben. Ungefähr in der Mitte der Kurven ist je ein weiterer Ankerpunkt eingefügt worden, mit diesen Punkten werden die Kurven in der Mitte verschoben, so dass sich am Messpunkt ein möglichst neutrales Grau ergibt. Photoshop macht das mehr oder weniger erfolgreich, weder Helligkeit noch Farbton sind richtig gut getroffen.
Im Prinzip kann ich manuell über die Kurven korrigieren, indem ich die Mittelpunkte in zwei Richtungen solange verschiebe, bis die Werte passen. Dabei wird jedoch schnell klar, dass ich auch hier wegen der ganzzahligen Eingabewerte und seltsamen Verhaltens von Photoshop nie 100% treffen werde. Ich komme aber sehr nah ran und bin zufrieden.
Jetzt gibt es drei Punkte pro Kurve, die im Normalfall nicht mehr auf einer Geraden liegen. Konsequenterweise hat die Kurve jetzt entweder einen Knick, oder sie wird gebogen. Letzteres passiert in Photoshop standardmäßig. Es ist nicht wichtig, zu wissen, wie das genau gemacht wird. Wichtig ist aber, dass – Knick oder Kurve – sich natürlich die Werte an den anderen Stellen bis auf Kopf- und Fußpunkt auch ändern. Mit etwas Pech stimmen die Werte für Schwarz und Weiß jetzt wieder sichtbar nicht.
Wer jetzt glaubt, ich könnte rasch die Weiß- und Schwarzpunkt-Pipetten verwenden, um Fuß- und Kopfpunkt der Kurven noch zu optimieren, der liegt leider falsch. Diese beiden löschen die mittleren Ankerpunkte, damit sind die angepassten Mittelwerte futsch. Weitere Feinabstimmungen müssen daher ab hier manuell geschehen.
Immer noch haben zwei der Kreise einen starken Stich. Der dunklere scheint zu blau, der hellere zu rot. Hier in diesem konstruierten Beispiel kann ich auch das noch korrigieren, indem ich weitere Ankerpunkte in die Kurven setze und diese weiter verbiege. Das ist hier aber auch noch vergleichsweise leicht, weil es ganz klare Referenzen gibt; ich weiß, wie das Bild aussehen muss. Die Feinabstimmung gelingt nicht perfekt, aber schon sehr gut.
Wenn ich ehrlich bin, habe ich jetzt nur von drei auf fünf Punkte erweitert, mich also etwas näher herangetastet. Es könnte immer noch Ausreißer zwischen den Punkten geben. Je mehr Referenzpunkte ich habe, desto besser wird das Ergebnis.
Bei Photographien kann man zwei Wege gehen. Entweder man verwendet eine Grautafel mit bekannten Grauwerten, photographiert diese bei der gleichen Beleuchtung wie das eigentlich Motiv und erzeugt sich damit eine Übersetzungskurve, oder man verlässt sich auf seine Erinnerung und versucht die Detailanpassungen „nach Gefühl“. Auf jeden Fall ist es sinnvoll, sich zu merken, welche Objekte oder Flächen des Originals weiß, schwarz oder neutral grau waren, dann kann man zumindest die hier beschriebenen Schritte umsetzen. Außerdem macht man am Besten vorab schon einen Weißabgleich, z.B. in Camera Raw oder Lightroom.
Ich habe hier den Prozess mit nur einer Korrekturebene gezeigt. Es gibt Photographen, wie eben auch Vincent Versace, die bis zu drei Ebenen übereinander legen, eine für den Schwarzpunkt, eine für den Weißpunkt, eine für die Mitteltöne. Das kann allerdings nicht wirklich gut funktionieren und nur subjektiv zufriedenstellende Ergebnisse produzieren, weil die einzelnen Schritte des Prozesses, wie ich gerade gezeigt habe, nicht unabhängig voneinander sind. Die Schwarzpunkt-Einstellung funktioniert noch, aber schon die Ebene für den Weißpunkt verschiebt das Ergebnis auch für den 3% Grau-Wert. Man kann nicht mehr unabhängig korrigieren, auch wenn die jeweiligen Autoren das behaupten. Ich lasse mich gern berichtigen, aber mein Eindruck ist, dass drei Ebenen nichts leichter machen. Was funktionieren kann ist eine Kombination von einer Ebene für Schwarz- und Weißpunkt und einer weiteren für die Mitteltöne. Es sei denn, die Abweichung in den mittleren Tönen ist so stark, dass dann die Krümmung der Kurven wiederum die 3% und 97% Punkte beeinflusst.
Ich werde versuchen, den Prozess in einem Folgeartikel noch einmal an einem Photo zu zeigen. Da wird klar werden, dass am Ende ganz andere Dinge wichtig sind als die technische Präzision der Farbstichkorrektur.

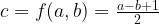


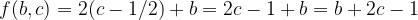

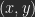 .
.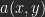 be the value (luminosity) of a pixel of image A,
be the value (luminosity) of a pixel of image A, 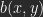 the value for a pixel of B with the same coordinates. As a result of a calculation you get a pixel-value of C:
the value for a pixel of B with the same coordinates. As a result of a calculation you get a pixel-value of C:  .
.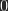 (zero)
(zero)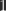 (one) for white, regardless of the actual bit depth. When calculating
(one) for white, regardless of the actual bit depth. When calculating 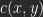 , you have to keep in mind that its value also is restricted to this interval.
, you have to keep in mind that its value also is restricted to this interval.![a,b,c \in [0,1]](http://s0.wp.com/latex.php?latex=a%2Cb%2Cc+%5Cin+%5B0%2C1%5D&bg=2a2a2a&fg=ffffff&s=1&c=20201002)
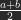 in PS by executing
in PS by executing 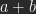 and
and  this, though it seems mathematically correct to do so.
this, though it seems mathematically correct to do so.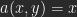 , defines a horizontal axis for a from 0 to 1), once from bottom to top (
, defines a horizontal axis for a from 0 to 1), once from bottom to top (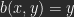 , the vertical axis from 0 to 1). This makes sure the result contains all possible combinations and we will see how smooth transitions are.
, the vertical axis from 0 to 1). This makes sure the result contains all possible combinations and we will see how smooth transitions are.


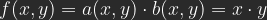


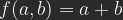

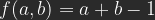
 and linear burn for
and linear burn for  . Not quite right, but close. If for
. Not quite right, but close. If for 
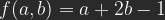

 for all pixels transfers image A unchanged to C when combined with this blend mode.
for all pixels transfers image A unchanged to C when combined with this blend mode.