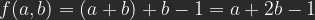Kürzlich habe ich mich mit der Methode der Frequenztrennung zur Retusche beschäftigt. Bei den Fstoppers habe ich einen einen interessanten Artikel dazu gefunden, der mich aber mit Fragen zurückgelassen hat. Eine war: warum ist Lineares Licht die richtige Verrechnungsmethode für die beiden Ebenen? Und direkt im Anschluss die Fragen, wo eigentlich der Unterschied zwischen Addition und Subtraktion bei der Bildberechung liegt und wieso man einen Unterschied zwischen 8bit und 16bit Bildern machen soll. Also wollte ich mir das mal genauer ansehen.
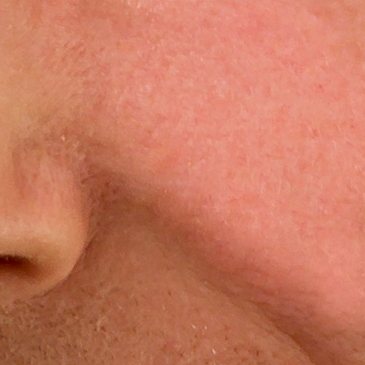
Ein Bild soll so in zwei zerlegt werden, dass das eine nur großflächige Veränderungen beinhaltet, das andere die feinen Strukturen. Bei einem Portrait z. B. soll das erste Bild nur Farben und große Strukturen wie Schatten beinhalten, die Hautstruktur soll sich im anderen wiederfinden. Die beiden Bilder sollen sich nachher über Ebenenverrechnung wieder zu einem zusammensetzen lassen, das sich nicht vom Original unterscheidet.
Warum? Weil man dann getrennt Korrekturen nur z. B. an der Hautfarbe machen kann, ohne die Struktur zu verändern und umgekehrt. Nicht modifizierte Stellen ergeben das Original, an den Stellen, wo man retuschiert, sieht das Ergebnis sehr natürlich aus.
Frequenzen
Feine Strukturen bedeuten eine rasche Änderung der Helligkeitswerte, einen starken lokalen Kontrast. Man kann die Änderungen als Überlagerung von Wellen in der Fläche sehen. Die feinen Strukturen bedeuten dann hohe Frequenzen, während die Änderungen über größere Abstände niedrige Frequenzen bedeuten.
Frequenzfilter in Photoshop
Photoshop kennt einen Hochpassfilter, dessen Aufgabe es ist, feine Strukturen aus dem Bild zu holen. Es gibt auch Tiefpassfilter, die allerdings nicht so heissen. Was tut man, wenn man feine Strukturen, also die hohen Frequenzen, verschwinden lassen will? Man verwendet einen Weichzeichner (Blur). Welcher ist eigentlich egal, bei Filtern wie Matter Machen (Surface Blur) oder Selektiver Weichzeichner (Smart Blur) muss man allerdings etwas aufpassen, da hier scharfe Kanten entstehen, die eigentlich für hohe Frequenzen stehen.
Bild zerlegen
Am Anfang gibt es ein Bild A, davon erzeugt man zwei Kopien. Nun verändert man die eine Kopie, so dass ein neues Bild B entsteht, z. B. mit einem Weichzeichner. Wie genau ist zunächst egal. Für das Beispiel habe ich einen Gaussschen Weichzeichner mit 6-Pixel-Radius verwendet.
Nun wird ein weiteres Bild C erzeugt, dass nur die Unterschiede zwischen A und B beinhaltet. Das sollte einfach sein, man muss nur die Differenz bilden. Praktisch macht man mit dem Menübefehl Bildberechnung (Apply Image) mit A als Ziel und C als Quelle.
Nun ist aber zu beachten, dass Photoshop als Ergebnis einer Rechung nur Werte zwischen 0 und 1 zulässt und alle anderen Werte abschneidet. Das ist bei der Differenzenbildung sehr ungünstig, insbesondere, wenn die Bilder sehr ähnlich sind. Also dividiert man durch 2 und verschiebt um ½ nach oben, dann bleibt die komplette Information erhalten.
.
Dass dem so ist, sieht man leicht, wenn man sich die Extreme ansieht, also Kombinationen von .
Anmerkung
In Photoshop kann man mit 8-bit, 16-bit oder auch 32-bit pro Pixel und Farbe arbeiten. Die oben verwendete 1 entspricht dann 255, 65536 oder 4294967295. Der Dialog Bildberechnung (Apply Image) bietet für die Methode Differenz zwei Parameter an zum Skalieren und zum Verschieben. Zum Skalieren benötigt man die 2, das ist der oben genannte Divisor. Bei der Verschiebung kann man leider nicht 0,5 eintragen, sondern muss den entsprechenden 8-bit Wert verwenden, die 128, unabhängig von der Bit-Tiefe des Bildes. Das führt immer wieder zu Verwirrung, weshalb man auf manchen Webseiten den Hinweis findet, man solle im 16-Bit-Fall das Bild B unbedingt invertiert mit Skalierung 2 zu A addieren. Mathematisch ist das identisch, praktisch habe ich auch keinen Unterschied erkennen können, weder bei 8-bit noch bei 16-bit.
.
Bild zusammensetzen
Jetzt gilt es noch, eine Formel zu finden, die die beiden Bilder B und C wieder zusammensetzt, so dass sich A ergibt. Einfach zusammenzählen geht natürlich nicht, weil skaliert und verschoben worden ist. Was ist zu tun? Ganz einfach: C verdoppeln, zu B hinzuzählen und 1 abziehen.
In der Praxis wird man nicht einfach mit Bildberechnung (Apply Image) aus den mühsam getrennten Bildern gleich wieder eins machen. Man wird beide Bilder als Ebenen übereinanderlegen, B nach unten, C nach oben, und für C den Verrechnungmodus Lineares Licht wählen. So behält man zwei Ebenen, die man getrennt bearbeiten kann. Man kann auch weitere Ebenen dazwischenschieben, z.B. für die Korrektur von Hauttönen oder einzelnen zu hellen oder dunklen Stellen. Ab hier wird es Retusche, und darum soll es in diesem Artikel nicht gehen.
Kürzlich habe ich mich mit der Methode der Frequenztrennung (frequency separation) zur Retusche beschäftigt. Bevor ich mir die Methode verständlich machen konnte, musste ich mich erst mal mit den Verrechnungsmodi (Blend Modes) in Photoshop vertraut machen. Dazu gibt es eine Menge zu finden und zu sagen. Ich will einfach anfangen und versuchen, meine Ergebnisse verständlich darzustellen, denn man findet eine Menge von Seiten im Web, die sich mit den Verrechnungsmodi bei Photoshop beschäftigen, die man aber nicht verstehen kann. Manche der Erklärungen sind leider schlicht falsch, oft zu kompliziert. Insbesondere Fotografen und Photoshop-Anwender nehmen es nicht sehr genau mit den Formeln. Da ich verstehen wollte, was wirklich gemacht wird, habe ich mir einige genauer angesehen. Dabei habe ich feststellen müssen, dass nicht alle Hersteller das gleiche meinen, wenn sie z. B. von Weiches Licht (Soft Light) sprechen. Adobe ist sicher der Platzhirsch, aber gerade bei Photoshop sind die Verfahren zum Teil eher schlecht implementiert.
Aufgabenstellung
Aus zwei Bildern ist ein neues zu berechnen. Dabei ergibt sich der Wert eines Pixels im Zielbild aus den Werten der entsprechenden Pixel der beiden Quellbilder. Verwendet wird das u. a., wenn in Photoshop mehrere Ebenen übereinander gelegt werden. Die einfachste, aber auch uninteressanteste Variante ist, die oberen Ebenen deckend zu machen, dann sieht man nur die oberste. Man kann aber auch andere Verrechnungsvorschriften nutzen und Farbe oder Helligkeit bzw. Kontrast des Bildes in der unteren Ebene mit der oberen Ebene manipulieren. Dafür nutzen es Fotografen.
Voraussetzungen und Definitionen
Der Einfachkeit halber arbeite ich hier zunächst nicht mit Farben, sondern nur mit der Helligkeit, also Schwarzweiß. Das ändert nichts an der Gültigkeit der Betrachtung, die Rechnung bei einem RGB-Bild ist für jeden Kanal einzeln durchzuführen. Die Transparenz eines Bildes (Alpha-Kanal) ignoriere ich zunächst auch.
Ich bezeichne die Quellbilder als A und B, das Zielbild als C. Wenn man an Ebenen denkt, wäre A die untere Ebene, B die obere. Ein gemeinsames rechtwinkliges Koordinatensystem sei definiert durch Abzählen der Pixel des Bildes. Der Ort eines Pixels ist bestimmt durch seine Koordinaten
sei der Helligkeitswert eines Pixels aus A, der eines Pixels aus B mit denselben Koordinaten. Das Ergebnis einer Berechnung ist
.
Ich lasse im Folgenden zur leichteren Lesbarkeit die Koordinaten weg, solange nur Pixel mit identischen Koordinaten verwendet werden.
Die Helligkeitswerte werden unabhängig von der Bit-Tiefe der Bilder angegeben als Zahlen zwischen (Null) für Schwarz und (Eins) für Weiß. Bei der Berechnung von Helligkeitswerten ist zu beachten, dass auch c zwischen und liegen muss.
Eine Schwierigkeit ist sofort zu erkennen: es gibt eine Vielzahl von Möglichkeiten, zwei Zahlen zwischen 0 und 1 zu verrechnen und dabei Werte außerhalb des erlaubten Bereiches zu erhalten. Bei allen Verrechnungen wird in Photoshop ganz einfach vorgegangen: Werte kleiner 0 werden durch 0 ersetzt, Werte größer 1 durch 1. Das hat hässliche Folgen, wenn man mehrere Verrechnungen hintereinander einsetzt, da Information verloren geht. So kann man in Photoshop leider nicht durch Hintereinanderausführen von und erreichen.
Darstellung
Zur Visualisierung verwende ich zwei Bilder, die miteinander verrechnet werden sollen. Diese enthalten alle Helligkeitswerte zwischen 0 und 1 als linearen Verlauf, einmal von rechts nach links (, gibt mir eine horizontale Achse für a von 0 bis 1) und einmal von unten nach oben (, vertikale Achse von 0 bis 1).
Bild ABild B
Verrechnungsmethoden
Ich möchte zunächst ein paar einfach, aber nicht völlig triviale Methoden betrachten, die Multiplikation und Addition, dann eine Kombination von beidem und zum Schluß dieses Teils eine Variante, die abhängig vom Helligkeitswert der Pixel in B zwei unterschiedliche Formeln verwendet.
Multiplikation (Multiply)
Die Multiplikation ist eine der einfachsten Verrechnungen, weil die Funktion keine Werte außerhalb des Intervalls 0 bis 1 liefert. Photoshop verwendet übrigens wirklich die Multiplikation, nicht das geometrische Mittel.
Das Ergebnis liegt wieder zwischen 0 und 1.
Bei meinen Testbildern ergibt sich:
Zwei Kanten und damit drei der Ecken sollten Schwarz sein, weil eine Multiplikation mit 0 immer 0 ergibt. Weiß ergibt sich nur in der oberen rechten Ecke.
Multipliziert
Ausflug: Geometrisches Mittel (nicht in Photoshop verfügbar)
Das geometrische Mittel
wäre für mich eigentlich die bessere Variante. Es ergäbe sich längs der Diagonale ein hübsch linearer Verlauf.
Linear Abwedeln (Linear Dodge)
Linear Abwedeln entspricht der Addition. Es ist sofort klar, dass die Addition zweier Zahlen zwischen 0 und 1 Ergebnisse zwischen 0 und 2 liefert. Die Hälfte der Ergebnisse werden also bei 1 abgeschnitten. Bei Fotos kann das zu leicht ausgebrannten Flächen führen.
Wenn die Summe von a+b größer wird als 1, wird für f 1 angenommen. Werte unter 0 sind nicht erreichbar, auf dieser Seite wird also nicht abgeschnitten. Man erwartet daher Weiß auf und oberhalb der Diagonale von oben links nach unten rechts, darunter einen linearen Verlauf zu Schwarz.
Linear Abwedeln
Linear Nachbelichten (Linear Burn)
Lineares Nachbelichten ist das negative inverse von Linearem Abwedeln. Es gibt die gleichen Probleme, Tiefen können leicht absaufen.
Wenn die Summe von a und b kleiner ist als 1 wird f kleiner als 0, dann wird 0 angenommen. Werte über 1 sind nicht erreichbar, auf dieser Seite wird nicht abgeschnitten. Man erwartet daher Schwarz auf und unterhalb der Diagonale von oben links nach unten rechts. Darüber einen linearen Verlauf zu Weiß.
Linear Nachbelichten
Lineares Licht (Linear Light)
Lineares Licht findet man oft beschieben als eine Kombination von Linearem Abwedeln für und Linearem Nachbelichten für . Das ist nicht ganz richtig, aber fast. Wenn man die Formel für Lineares Nachbelichten für auf der b-Achse um den Faktor 2 staucht und um 1/2 verschiebt und die für Lineares Nachbelichten für auch mit dem Faktor 2 auf der b-Achse staucht, dann erhält man tatsächlich:
Oder nach Auflösen halt einfach:
Die Verrechnung ist nicht mehr kommutativ, man kann also A und B nicht tauschen.
Auf der linken Kante (a=0) erwartet man von unten nach oben Schwarz bis b=0,5, danach einen linearen Verlauf zu Weiß. Auf der unteren Kante (b=0) nur Schwarz, weil die -1 alle möglichen Ergebnisse negativ macht. Mit b= 1 ergibt sich auf der oberen Kante ein durchgängiges Weiß. Auf der rechten Kante (a=1) erhält man von unten nach oben einen linearen Verlauf von Schwarz zu Weiß bei b=0,5.
Lineares Licht
Interessant für die Verwendung in Photoshop ist, dass ein Bild B mit durchgehend das Bild A bei dieser Verrechnung unverändert in C übernimmt. Die neutrale Farbe für B für Lineares Licht ist 50% Grau. Lineares Licht wird gern verwendet, um ein Foto mit einer fast grauen Ebene mit geringen Abweichungen zu manipulieren, z. B. bei dem sogenannten Frequenztrennungs-Verfahren.
Die Methode lässt sich darstellen als das Ergebnis von beiden Verrechnungsmethoden nacheinander angewandt (bei zweifacher Verwendung von B), oder auch einfach als Lineares Nachbelichten mit verdoppeltem B (das lässt sich leider in Photoshop nicht so einfach mit mehreren Einzelschritten bewerkstelligen, da auch Zwischenergebnisse außerhalb 0 und 1 abgeschnitten werden).
Vincent Versace, dessen Buch Welcome to Oz 2.0 ich gerade durcharbeite, ist ein großer Freund von vorgefertigten Effekten, z.B. von Nik (jetzt leider Google) oder OnOne. Ich habe bislang immer Abstand genommen von diesen Dingen, weil mir die Ergebnisse immer zu spektakelig daher kamen. Jetzt habe ich probehalber mal angefangen, damit zu spielen. Noch bin ich unbegeistert. Viele der Effekte sehen aus wie Instagram quadriert. Ich kann sehr schnell Bilder produzieren, die so aussehen wie viele andere auch. Eine Art moderner Pseudo-Retro Look mit Pseudo-Analogfilm-Anmutung, Pseudo-Cross-Processing abgerundet mit einem Pseudo-Glasnegativ-Grunge-Rahmen.
Gefällt mir das? Nein! Ich frage mich natürlich, warum mir das nicht gefällt. Weil es so aussieht wie vieles? Nicht wirklich. Es gibt so viele Photographen, da ist es schwer, immer was Originelles zu produzieren, was noch nie da war. Ich denke, es liegt daran, dass man die Effekte so deutlich sieht. Es ist zu einfach, niemand muss sich die Mühe machen, lange an einem Bild zu arbeiten. Nun bedeutet langes Arbeiten natürlich noch lange nicht hohe Qualität. Aber es bewirkt, dass man gezwungen ist, sich länger mit dem Objekt zu beschäftigen, mehr nachzudenken – auch mehr über das Warum und Was, nicht nur über das Wie.
Alles in allem sind die Werkzeuge vermutlich nützlich und gut, wenn in der richtigen Dosierung eingesetzt. Also dann, wenn ich verstanden habe, warum ich einen Effekt haben will, wenn ich ihn einsetze, weil ich eine Idee habe, und wenn ich der Versuchung widerstanden haben, den Effekt einfach nur deswegen zu verwenden, weil es ihn gibt. Und die Versuchung ist groß: Foto oben rein, ein halbes Dutzend Effekte ausprobiert, sieht geil aus, Rahmen drum und ab auf facebook. Je weniger geplant das Bild aussieht, desto Kunst. Mein Ansatz ist das nicht. Ich werde mir die Effekte dennoch etwas genauer ansehen, vielleicht ist etwas dabei, was ich brauchen kann. Vielleicht spare ich in dem einen oder anderen Fall eine mühevolle Maskenerstellung, wenn die Kontrollpunkte von Nik Effects das gleiche erreichen. Vielleicht, wenn ich es brauchen kann und es zum Bild passt.
Das gilt natürlich auch für alle Spielereien, die ich in LightRoom und Photoshop schon ohne Plug-In kann. Ist es eine gute Idee, einer Digitalaufnahme ein künstliches Filmkorn hinzuzufügen? Warum soll man eine Schwäche der alten Filme imitieren? Was tut man dabei eigentlich? Man imitiert eine Ästhetik. Das gleiche gilt für Cross-Processing und, wenn man noch weiter gehen will, auch für schwarz-weiß Aufnahmen. Bitte nicht falsch verstehen: ich verdamme nicht etwas die Schwarz-Weiß-Photographie. Aber man muss sich klar darüber sein, was man da tut. Wie stützt die Entscheidung das Bild? Setze ich die künstliche Vignette ein, weil sie so schön historisch wirkt und damit das Bild älter ( = wertiger) wirken lässt oder weil ich damit den Blick ins Zentrum lenken und ein wenig von der strengen Rechteckigkeit des Formats aufheben kann?
Wir sollten und als Digitalphotographen nicht minderwertig fühlen und der guten alten Zeit hinterherhecheln. Und wenn wir wirklich den Look eines Analogfilmes wollen, dann sollten wir analog arbeiten und die Dunkelkammer wieder rauskramen. Für mich bleibt ein Foto mit fiesem Grün-Gelbstich ein Foto mit Grün-Gelbstich. Ich war in den 70ern schon auf der Welt, ich brauch das nicht als Retro-Look.
Ich lese gerade ein Buch von Vincent Versace namens Welcome to Oz 2.0. Schon das erste Kapitel hat mich mächtig zum Grübeln gebracht. Ich mag seinen Ansatz, das sorgfältige Vorgehen. Er macht erst einen Plan, stellt sich die Frage, warum er etwas tut, was er erreichen will, bevor er den großen Werkzeugkasten herausholt. Mit seiner Art der Farbstichkorrektur bin ich aber gar nicht einverstanden. Also habe ich mir das mal genauer angesehen und versucht, zu verstehen, was Photoshop wie tut und wie man das einsetzen kann.
Meine Erkenntnisse kann man am einfachsten an einem simplen Beispiel nachvollziehen. Ein Photo ist herzlich ungeeignet, also habe ich mal etwas vorbereitet. In dem folgenden Beispielbild sieht man zwei Reihen Kreise. Die zweite Reihe ist das Original, der ersten Reihe wurde ein Farbstich gegeben und der Kontrast wurde reduziert. Aufgabenstellung ist nun, zu versuchen, mit Hilfe von Photoshop Gradationskurven das Bild möglichst nahe an das Original zu bringen. Insofern ist die zweite Reihe auch das Ziel, da will ich hin. Die Originalkreise haben Grauwerte von 3%, 27%, 50%, 73% und 97%. Der Hintergrund ist 50% Grau, weshalb auch der mittlere Kreis in der zweiten Reihe verschwindet.
Meine Aufgabenstellung
Die Chancen für eine erfolgreiche Korrektur sind gut: ich weiß etwas über das Bild, das ich korrigieren soll, ich habe eine Referenz. Das ist wichtig, denn ansonsten bleibt eigentlich nur das Erraten des Zieles.
Messen
Irgendwo muss man anfangen. Ich fange an, indem ich daran glaube, dass mein Monitor gut kalibriert ist und einen gleichförmigen Grauverlauf zeigt, dass also das, was ich als RGB Werte der einzelnen Pixel messen kann, auch dem entspricht, was ich sehe. Letztendlich ist das aber auch egal, denn bei dem, was die Werkzeuge tun, geht es nur um die Werte, nicht um das, was ich sehe.
Also fange ich mit dem Messen an. Ich setze mit dem Pipetten-Werkzeug drei Farbmesspunkte. Dazu klicke ich mit gehaltener Umschalt-Taste auf die gewünschten Stellen.
Es ist zu erkennen, dass die Messwerte noch deutlich von den Zielwerten 3% Grau, 97% Grau und 50% Grau abweichen. Die gesetzten Messpunkte werden mir dazu dienen, meine Arbeit bei der Korrektur zu überprüfen.
Eine Anmerkung an dieser Stelle: eigentlich mache ich hier schon den ersten Fehler, denn ich überprüfe nur drei Stellen, in der stillschweigenden Hoffnung, das die Farb- und Helligkeitsfehler keiner allzu wilden Verteilung folgen. Bei realen Aufnahmen von modernen Digitalkameras kann man das üblicherweise voraussetzen, ohne allzu weit daneben zu liegen.
Schwarzpunkt
Zunächst soll der Schwarzpunkt korrigiert werden. Dazu lege ich eine Korrekturebene über die bestehenden Ebenen. Ich wähle die Gradationskurven, beschränke die Korrekturen gleich auf die darunterliegende Ebene, die mein Fehlerbild enthält, damit Hintergrund und Zielbild nicht beeinflusst werden.
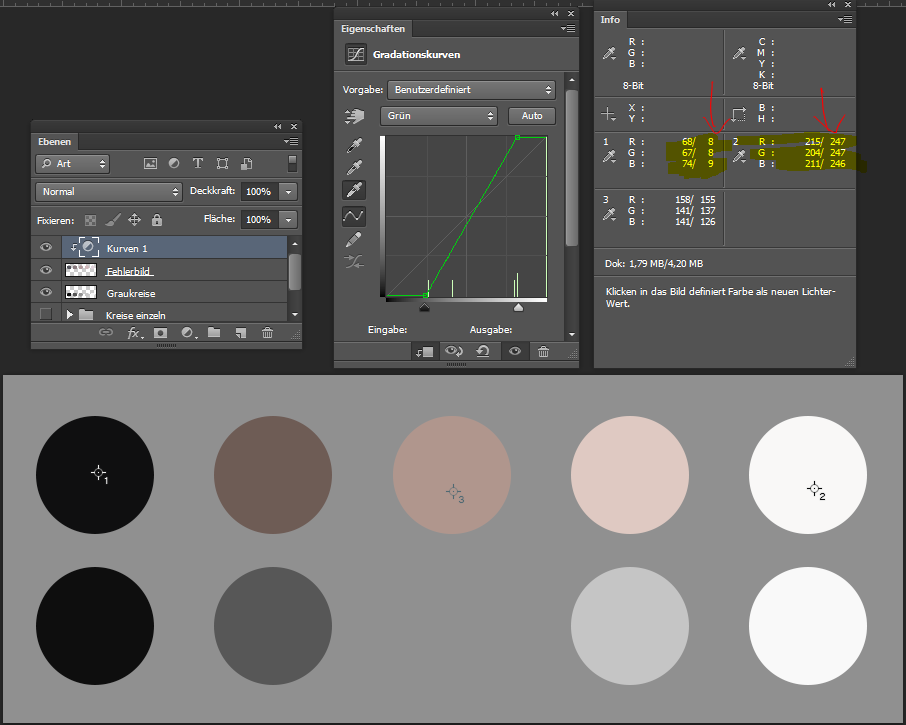
Nun prüfe ich als erstes den Zielwert für den Schwarzpunkt, die sogenannte Zieltiefenfarbe. Dazu mache ich einen Doppelklick auf das oberste der drei Pipetten-Symbole.
Das Ziel ist eingestellt auf 3% Grau, passt perfekt. Das Fenster kann wieder geschlossen werden.
Jetzt verwende ich die Umschalt-Feststellen-Taste, um meinen Mauszeiger in ein Fadenkreuz zu verwandeln, wähle mit einem Einfachklick die obere Pipette aus. Mit einem Rechtsklick ins Bild öffne ich das Kontextmenü, mit dem man die Größe der Pipettenspitze auswählen kann. Da echte Bilder fast immer ein leichtes Rauschen enthalten, halte ich es für sinnvoll, mehr als ein Pixel aufzunehmen und daraus den Mittelwert zu bilden, ich wähle daher den 3×3 Pixel Durchschnitt.
Nun klicke ich einmal möglichst genau auf meinen Farbmesspunkt 1. Hier in diesem Fall hätte es natürlich gereicht, irgendwo in den Farbkreis zu klicken. Bei Fotos sind die Farbflächen jedoch meist nicht so schön groß und gleichförmig, da sollte man dann schon den vorher mühsam herausgesuchten Messpunkt genau treffen. Dabei hilft der Fadenkreuz-Mauszeiger.
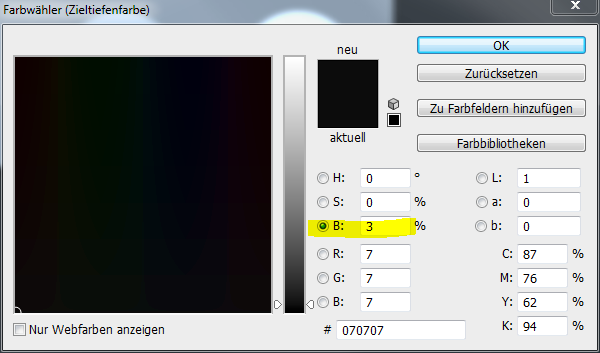
Das Ergebnis ist ein schöner schwarzer Kreis, wie gewünscht. Interessanterweise zeigen die Messwerte, dass das Ziel von 3% (entspricht RGB 070707) nicht ganz getroffen wurde.
Warum wird klar, wenn man sich ansieht, was das Schwarzpunkt-Werkzeug getan hat. Dazu sehe ich mir die Kurven genauer an.
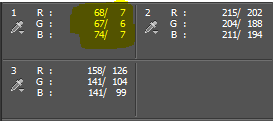
Die weiße Linie steht für die RGB-Summe, hier hat sich nichts geändert, aber bei den Linien für die einzelnen Farben Rot, Grün und Blau. Hier sind die Fußpunkte unterschiedlich weit nach rechts verschoben worden. Die Linien selber sind weiterhin gerade, haben aber in Folge eine stärkere Steigung. Was heißt das?
Die Linien stehen für eine Übersetzung eines alten Wertes (horizontale Achse) in einen neuen Wert (vertikale Achse). Alle Werte im Originalbild zwischen 0 und dem Fußpunktwert werden auf 0 abgebildet, alle darüber auf neue Werte größer 0. Betrachten wir den Wert für Rot für den linken Kreis. Der alte Wert war 68, der neue ist 7, wie gewünscht. Die Übersetzung erfolgt im Prinzip so, dass man auf der horizontalen Achse zur 68 geht, dann nach oben zur roten Linie, dann nach links zur vertikalen Achse und dort den neuen Wert 7 abliest. Wenn man den Mauszeiger über den Kurven schweben lässt, kann man die Werte als „Eingabe“ und „Ausgabe“ anzeigen lassen.
Bei Grün passt die Übersetzung nicht optimal. Das liegt daran, dass man den Fußpunkt, wenn man mit 8bit Kurvenanzeige arbeitet, nicht genau genug verschieben kann, um den Punkt (67,6) mit der grünen Linie zu treffen. Ich versuche es noch mal, um zu zeigen, was ich meine. Dazu schalte ich um auf die Grün-Kurve, markiere den Fußpunkt mit einem Mausklick und versuche, ich mit den Pfeiltasten so zu schieben, dass mein Messpunkt für Grün auch 7 meldet.
Das gelingt mir leider nicht, ich erreiche wegen der erzwungenen Ganzzahligkeit des Eingabewertes nur entweder 6 oder 8.
Was habe ich gelernt:
Die Schwarzpunkt-Pipette verschiebt den Fußpunkt der Gradationskurve für jede Farbe einzeln so, dass bei der Übersetzung mit den entstehenden Kurven die gewünschten Zielwerte für meine angeklickten Quellwerte möglichst genau getroffen werden.
Der Fußpunkt legt den höchsten Quellwert fest, dem noch der Zielwert 0 zugewiesen wird. Das ist nicht der Punkt, der sich aus den gemessenen Quellwerten und festgelegten Zielwerten ergibt, also nicht der angestrebte 3% Grau-Wert.
Auch wenn ich den Zielwert für meinen Schwarzpunkt auf 3% Grau festgelegt habe, heißt das nicht, dass es im Bild nicht noch dunklere Punkte geben kann, die aber noch nicht vollständig schwarz sein müssen. Findet sich z.B. ein Punkt, der für Rot den Wert 64 hat, dann wird dieser den Zielwert 2 erhalten, nicht 0.
Wenn mein Originalbild Punkte mit Quellwerten unterhalb des Fußpunktes enthält, dann werden diese alle auf 0 gesetzt. Wenn es sich nur um einzelne Punkte oder kleine Flächen handelt, ist das vergleichsweise egal. In der Praxis heißt das aber meist, dass sich unschöne zusammenhängende Flächen bilden, die alle den Wert 0 haben. Man kann keine Details mehr erkennen, keine Struktur, keine sogenannte „Zeichnung“, Diese Stellen bezeichnet man als „abgesoffen“.
Im Idealfall sind alle dunklen Flächen „durchgezeichnet“, das heißt, man kann überall noch Strukturen erkennen. Das ist auch der Grund, warum ich als Zielwert für den Schwarzpunkt 3% Grau und nicht echtes Schwarz gewählt habe: ich verschaffe mir eine Reserve, die verhindert, dass später z.B. beim Druck die Tiefen nicht „zulaufen“.
Anmerkung dazu: ich halte es in Abhängigkeit vom Inhalt des Bildes für durchaus in Ordnung, schwarze Flächen zu erzeugen. Wo kein Licht ist, kommt auch keins her. Die Entscheidung, ob man das macht oder nicht, muss man für jedes Bild treffen. Da, wo man Zeichnung haben will, da sollte es halt nicht nur schwarz sein.
Weißpunkt
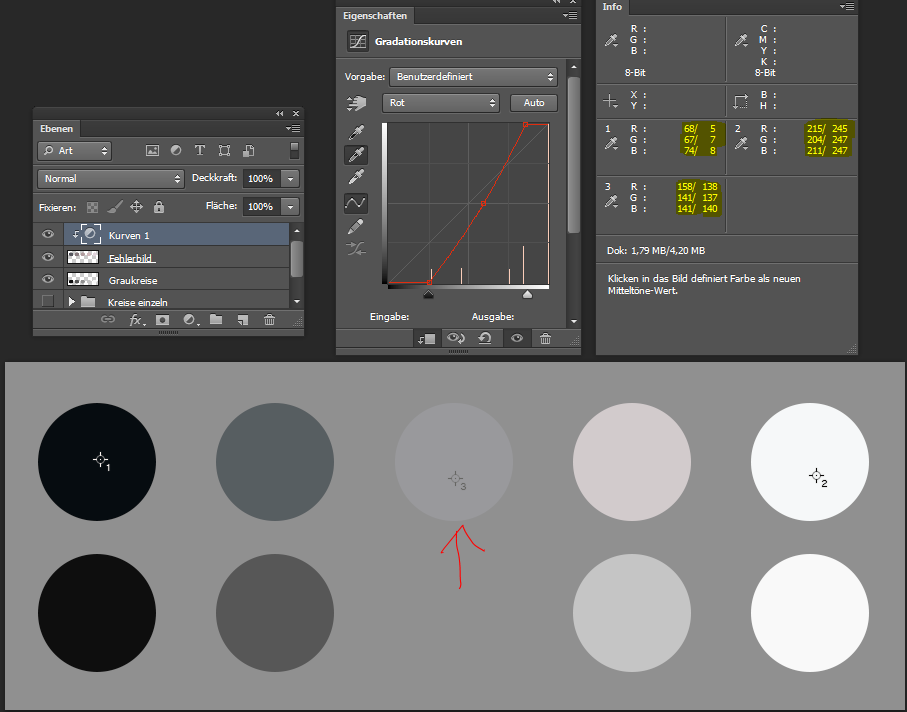
Im nächsten Schritt mache ich analoge mit dem Weißpunkt weiter. Ich lege den Zielwert auf 97% Grau fest, klicke dann mit der Weißpunkt-Pipette in den rechten Kreis, der sofort weiß erscheint.
Auch hier wird der Zielwert nicht exakt getroffen, aber ich bin nah dran. Bemerkenswert ist, dass sich die Messwerte für das schwarze Feld verändert haben. Das ist so, weil der Schwarzpunkt kein Ankerpunkt der Kurve ist. Beim Einstellen des Schwarzpunktes wurde der Fußpunkt verschoben, so dass der gewünschte Schwarzpunkt, oder besser 3%-Grau-Punkt, auf der Kurve zu liegen kommt. Nun wird auch noch der Kopfpunkt so verschoben, dass der Weißpunkt getroffen wird. Ergebnis: die Kurve wird steiler. Sie beginnt aber immer noch beim selben Fußpunkt, muss also den alten Schwarzpunkt verfehlen.
Das kann dazu führen, dass man sich einen neuen Farbstich einschleppt. Zum Glück kann ich leicht korrigieren indem ich den Vorgang für den Schwarzpunkt einfach noch mal ausführe. Der Fußpunkt wird noch mal angepasst, allerdings ist die Änderung an der Kurve diesmal so gering, dass sich für den Weißpunkt nichts mehr groß ändert.
Als Ergebnis sind die äußeren Kreise optimal korrigiert, mit dem bloßen Auge vom Original nicht mehr zu unterscheiden. Die Grautöne dazwischen leider sind noch nicht so schick.
Mitteltöne
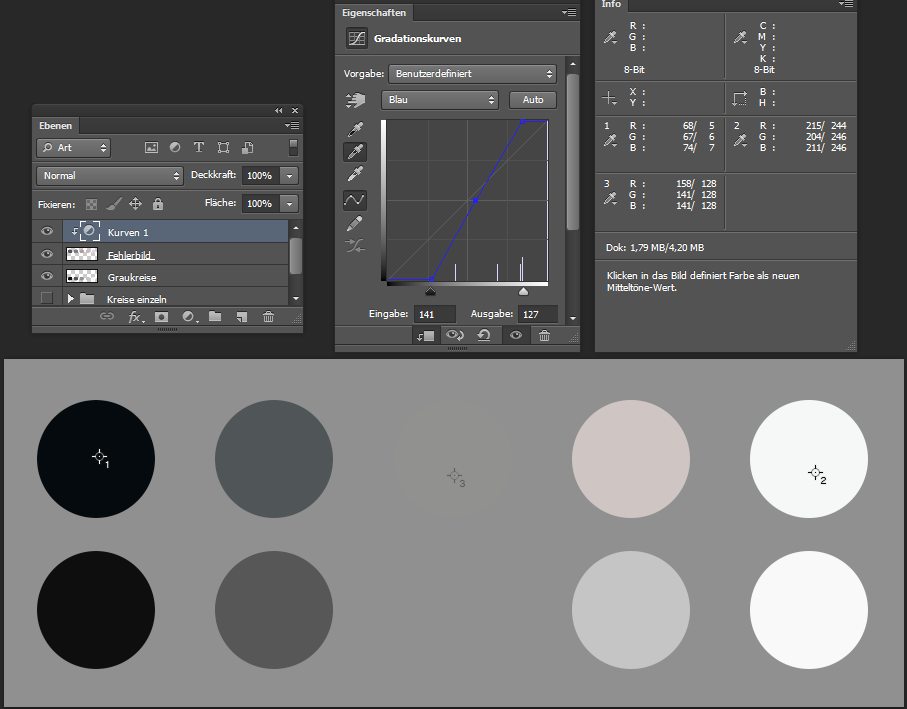
Jetzt kommt die letzte Pipette zum Einsatz, die für die Mitteltöne. Sie funktioniert anders als die beiden anderen. Bei Weiß- und Schwarzpunkt werden Helligkeit, Sättigung und Farbton der Quelle in die des Zieles übersetzt, bei den Mitteltönen spielt die Helligkeit der Quelle keine Rolle, nur Farbton und Sättigung. Da ich aber den Farbstich der Mittelwerte korrigieren will und nicht den der Tiefen oder Lichter messen, verwende ich am Besten eine Quelle, die korrigiert möglichst ein neutrales Mittelgrau haben soll. Es ist nicht entscheidend, welche Farbe diese Stelle in der farbstichigen Aufnahme hat, wichtig ist, dass sie in Natura neutral grau war. Im Beispiel ist das der mittlere Kreis.
Ich kontrolliere sicherheitshalber noch mal den Zielwert, der sollte hier ein 50% Grau sein, und klicke dann mit der Mittelwert-Pipette in den mittleren Kreis. Das Ergebnis ist zunächst überraschend.
Was fällt auf:
man kann den mittleren Kreis noch sehen. Wenn er wirklich auf Mittelgrau korrigiert worden wäre, müsste er auf dem Hintergrund verschwinden.
Die Werte des dritten Messpunktes sind alle deutlich größer als 128 und deutlich unterschiedlich.
Die beiden Kreise rechts und links der Mitte haben immer noch einen Farbstich, wenn auch weniger als vorher.
Die Werte der Messpunkte 1 und 2 haben sich auch noch mal geändert.
Es ist einfach zu verstehen, was jetzt passiert ist. Kopf- und Fußpunkte der Kurven sind fest geblieben. Ungefähr in der Mitte der Kurven ist je ein weiterer Ankerpunkt eingefügt worden, mit diesen Punkten werden die Kurven in der Mitte verschoben, so dass sich am Messpunkt ein möglichst neutrales Grau ergibt. Photoshop macht das mehr oder weniger erfolgreich, weder Helligkeit noch Farbton sind richtig gut getroffen.
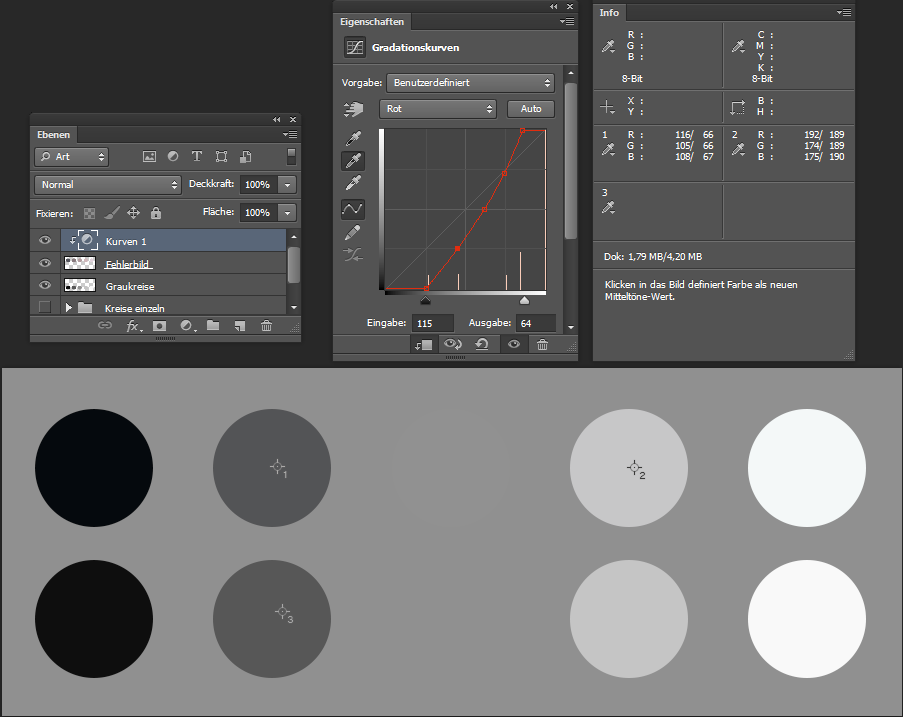
Im Prinzip kann ich manuell über die Kurven korrigieren, indem ich die Mittelpunkte in zwei Richtungen solange verschiebe, bis die Werte passen. Dabei wird jedoch schnell klar, dass ich auch hier wegen der ganzzahligen Eingabewerte und seltsamen Verhaltens von Photoshop nie 100% treffen werde. Ich komme aber sehr nah ran und bin zufrieden.
Jetzt gibt es drei Punkte pro Kurve, die im Normalfall nicht mehr auf einer Geraden liegen. Konsequenterweise hat die Kurve jetzt entweder einen Knick, oder sie wird gebogen. Letzteres passiert in Photoshop standardmäßig. Es ist nicht wichtig, zu wissen, wie das genau gemacht wird. Wichtig ist aber, dass – Knick oder Kurve – sich natürlich die Werte an den anderen Stellen bis auf Kopf- und Fußpunkt auch ändern. Mit etwas Pech stimmen die Werte für Schwarz und Weiß jetzt wieder sichtbar nicht.
Wer jetzt glaubt, ich könnte rasch die Weiß- und Schwarzpunkt-Pipetten verwenden, um Fuß- und Kopfpunkt der Kurven noch zu optimieren, der liegt leider falsch. Diese beiden löschen die mittleren Ankerpunkte, damit sind die angepassten Mittelwerte futsch. Weitere Feinabstimmungen müssen daher ab hier manuell geschehen.
Immer noch haben zwei der Kreise einen starken Stich. Der dunklere scheint zu blau, der hellere zu rot. Hier in diesem konstruierten Beispiel kann ich auch das noch korrigieren, indem ich weitere Ankerpunkte in die Kurven setze und diese weiter verbiege. Das ist hier aber auch noch vergleichsweise leicht, weil es ganz klare Referenzen gibt; ich weiß, wie das Bild aussehen muss. Die Feinabstimmung gelingt nicht perfekt, aber schon sehr gut.
Wenn ich ehrlich bin, habe ich jetzt nur von drei auf fünf Punkte erweitert, mich also etwas näher herangetastet. Es könnte immer noch Ausreißer zwischen den Punkten geben. Je mehr Referenzpunkte ich habe, desto besser wird das Ergebnis.
Bei Photographien kann man zwei Wege gehen. Entweder man verwendet eine Grautafel mit bekannten Grauwerten, photographiert diese bei der gleichen Beleuchtung wie das eigentlich Motiv und erzeugt sich damit eine Übersetzungskurve, oder man verlässt sich auf seine Erinnerung und versucht die Detailanpassungen „nach Gefühl“. Auf jeden Fall ist es sinnvoll, sich zu merken, welche Objekte oder Flächen des Originals weiß, schwarz oder neutral grau waren, dann kann man zumindest die hier beschriebenen Schritte umsetzen. Außerdem macht man am Besten vorab schon einen Weißabgleich, z.B. in Camera Raw oder Lightroom.
Ich habe hier den Prozess mit nur einer Korrekturebene gezeigt. Es gibt Photographen, wie eben auch Vincent Versace, die bis zu drei Ebenen übereinander legen, eine für den Schwarzpunkt, eine für den Weißpunkt, eine für die Mitteltöne. Das kann allerdings nicht wirklich gut funktionieren und nur subjektiv zufriedenstellende Ergebnisse produzieren, weil die einzelnen Schritte des Prozesses, wie ich gerade gezeigt habe, nicht unabhängig voneinander sind. Die Schwarzpunkt-Einstellung funktioniert noch, aber schon die Ebene für den Weißpunkt verschiebt das Ergebnis auch für den 3% Grau-Wert. Man kann nicht mehr unabhängig korrigieren, auch wenn die jeweiligen Autoren das behaupten. Ich lasse mich gern berichtigen, aber mein Eindruck ist, dass drei Ebenen nichts leichter machen. Was funktionieren kann ist eine Kombination von einer Ebene für Schwarz- und Weißpunkt und einer weiteren für die Mitteltöne. Es sei denn, die Abweichung in den mittleren Tönen ist so stark, dass dann die Krümmung der Kurven wiederum die 3% und 97% Punkte beeinflusst.
Ich werde versuchen, den Prozess in einem Folgeartikel noch einmal an einem Photo zu zeigen. Da wird klar werden, dass am Ende ganz andere Dinge wichtig sind als die technische Präzision der Farbstichkorrektur.

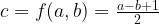
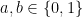


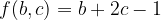

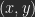
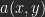 sei der Helligkeitswert eines Pixels aus A,
sei der Helligkeitswert eines Pixels aus A, 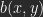 der eines Pixels aus B mit denselben Koordinaten. Das Ergebnis einer Berechnung ist
der eines Pixels aus B mit denselben Koordinaten. Das Ergebnis einer Berechnung ist .
. (Null) für Schwarz und
(Null) für Schwarz und 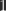 (Eins) für Weiß. Bei der Berechnung von Helligkeitswerten
(Eins) für Weiß. Bei der Berechnung von Helligkeitswerten 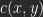 ist zu beachten, dass auch c zwischen
ist zu beachten, dass auch c zwischen 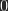 und
und ![a,b,c \in [0,1]](http://s0.wp.com/latex.php?latex=a%2Cb%2Cc+%5Cin+%5B0%2C1%5D&bg=2a2a2a&fg=ffffff&s=1&c=20201002)
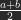 durch Hintereinanderausführen von
durch Hintereinanderausführen von 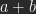 und
und  erreichen.
erreichen.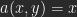 , gibt mir eine horizontale Achse für a von 0 bis 1) und einmal von unten nach oben (
, gibt mir eine horizontale Achse für a von 0 bis 1) und einmal von unten nach oben (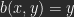 , vertikale Achse von 0 bis 1).
, vertikale Achse von 0 bis 1).


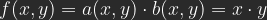


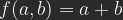

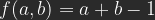
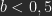 und Linearem Nachbelichten für
und Linearem Nachbelichten für 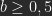 . Das ist nicht ganz richtig, aber fast. Wenn man die Formel für Lineares Nachbelichten für
. Das ist nicht ganz richtig, aber fast. Wenn man die Formel für Lineares Nachbelichten für 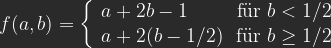
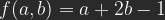

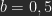 das Bild A bei dieser Verrechnung unverändert in C übernimmt. Die neutrale Farbe für B für Lineares Licht ist 50% Grau. Lineares Licht wird gern verwendet, um ein Foto mit einer fast grauen Ebene mit geringen Abweichungen zu manipulieren, z. B. bei dem sogenannten Frequenztrennungs-Verfahren.
das Bild A bei dieser Verrechnung unverändert in C übernimmt. Die neutrale Farbe für B für Lineares Licht ist 50% Grau. Lineares Licht wird gern verwendet, um ein Foto mit einer fast grauen Ebene mit geringen Abweichungen zu manipulieren, z. B. bei dem sogenannten Frequenztrennungs-Verfahren.